Optimizing Biomass Supply Chains for Drug Discovery: A GIS-Integrated Linear Programming Approach
This article explores the integration of Geographic Information Systems (GIS) and Linear Programming (LP) for optimizing biomass supply chains, a critical component in the early stages of drug discovery.
Optimizing Biomass Supply Chains for Drug Discovery: A GIS-Integrated Linear Programming Approach
Abstract
This article explores the integration of Geographic Information Systems (GIS) and Linear Programming (LP) for optimizing biomass supply chains, a critical component in the early stages of drug discovery. Targeted at researchers and drug development professionals, it provides a comprehensive guide from foundational concepts to advanced validation. We define the unique challenges of sourcing plant and microbial biomass for bioactive compound extraction. The core methodological framework demonstrates how GIS spatial data (on biomass availability, terrain, and infrastructure) feeds into LP models to minimize cost, maximize yield, and ensure sustainability. The guide addresses common data and model integration pitfalls, offers optimization strategies for real-world variability, and concludes with validation protocols and a comparative analysis against traditional planning methods. This synthesis offers a actionable roadmap for building efficient, scalable, and resilient biomass supply networks to fuel the pipeline of new therapeutics.
Why Biomass Sourcing is the Critical First Step in Modern Drug Discovery
The Role of Natural Biomass in Sourcing Novel Bioactive Compounds
Application Notes
Note 1: Integration with GIS-Linear Programming Supply Chain Models The discovery of novel bioactive compounds from natural biomass is critically dependent on a sustainable, optimized supply chain. A GIS-integrated linear programming (LP) model is essential for minimizing logistical costs (collection, transport) and environmental impact while maximizing biomass quality and diversity for bioprospecting. Key parameters fed into the model include:
- Spatial Data (GIS): Species distribution maps, land use/cover, road networks, terrain, protected areas.
- Economic & Logistical Data: Harvesting costs, transportation costs per km/ton, processing facility locations and capacities.
- Biomass Quality Data: Target metabolite seasonal variation, yield per unit area, conservation status.
- LP Objective Function: Typically minimizes total cost (harvest + transport) subject to constraints like biomass demand, capacity limits, and sustainable harvesting quotas.
Note 2: High-Throughput Ethnobotanical & Ecological Prioritization Biomass collection should be guided by both traditional knowledge (ethnobotany) and ecological theory (e.g., species in stressed environments may produce unique defensive compounds). GIS layers incorporating indigenous land use and ecological zones can prioritize collection sites, increasing the probability of discovering novel bioactives.
Note 3: Metabolomic-Guided Fractionation Modern discovery relies less on pure random screening and more on targeted approaches. LC-MS or NMR-based metabolomics of crude extracts compares chemical profiles against known compound databases. This "dereplication" quickly identifies novel chemistries, guiding the fractionation process and reducing redundant isolation efforts.
Table 1: Quantitative Metrics for Biomass Sourcing in Bioactive Compound Discovery
| Metric | Typical Range/Value | Importance for Discovery |
|---|---|---|
| Biomass Required for Initial Extract | 0.5 - 5 kg (dry weight) | Sufficient for primary bioactivity screening and metabolomic fingerprinting. |
| Hit Rate from Crude Extracts | 0.1% - 5% (varies by source/target) | Guides collection strategy; higher rates justify further investment in specific biomes/taxa. |
| Average Yield of Pure Compound | 0.001% - 0.1% (w/w of dry biomass) | Critical for supply chain calculation; determines biomass needed for preclinical development. |
| Optimal Transport Time (Fresh Biomass) | < 24-48 hours | Preserves labile metabolites; GIS-LP models optimize facility proximity. |
| Number of Fractions per Extract | 20 - 200 | Reflects complexity of the chemical space explored from a single source. |
Protocols
Protocol 1: GIS-LP Optimized Biomass Collection and Logistics
Objective: To collect, document, and transport natural biomass from field to laboratory using a supply chain optimized by a GIS-Linear Programming model. Materials: GPS device, digital data collection form, plant press/drying oven, sterile containers for microbial samples, liquid nitrogen dry shipper, standardized collection kit. Procedure:
- Site Selection: Input target species/ecosystem data into GIS. Overlay with road networks, land ownership, and conservation layers. Run LP model to identify optimal collection sites minimizing total cost while meeting biomass quantity/quality constraints.
- Field Collection:
- Navigate to pre-coordinated waypoints.
- Record exact GPS coordinates, habitat, phenology, and associated species.
- Collect biomass sustainably (following IUCN/MABS guidelines). For plants, collect voucher specimens (herbarium). For marine or microbial samples, use sterile techniques.
- Process biomass as required: immediate freezing in liquid nitrogen (for RNA/labile metabolites), air-drying, or solvent stabilization.
- Logistics & Transport:
- Package samples according to IATA regulations if applicable.
- Ship using the transport mode (road/air) and route determined by the LP model to the designated processing facility within the optimal time window.
- Data Management: Upload all collection metadata (location, date, weight, images) to the central GIS database linked to the extracted sample ID.
Protocol 2: Bioactivity-Guided Fractionation of Crude Biomass Extracts
Objective: To isolate a novel bioactive compound from a crude natural extract. Materials: Rotary evaporator, flash chromatography system, HPLC/UPLC system, analytical & preparative columns, fraction collector, 96-well assay plates, bioassay reagents. Procedure:
- Crude Extract Preparation: Lyophilize or oven-dry biomass. Perform sequential extraction using solvents of increasing polarity (e.g., hexane, dichloromethane, ethyl acetate, methanol/water). Concentrate extracts in vacuo.
- Primary Bioassay: Screen crude extracts in relevant biological assay (e.g., antimicrobial, cytotoxicity, enzyme inhibition). Identify "hit" extracts.
- Dereplication: Perform LC-MS/MS analysis of "hit" extract. Compare spectral data (MS/MS fragments, UV) with internal and public databases (e.g., GNPS) to flag known compounds.
- Fractionation:
- Step 1: Subject active crude extract to vacuum liquid chromatography (VLC) or flash column chromatography to obtain broad fractions (F1-Fn).
- Step 2: Test all fractions in the bioassay. Pool active fractions.
- Step 3: Further separate active pool using semi-preparative HPLC with a C18 column (gradient: H2O/MeCN + 0.1% formic acid).
- Step 4: Collect subfractions and re-assay. Repeat chromatographic steps (changing stationary phase if needed) until pure active compound is obtained.
- Structure Elucidation: Analyze pure compound using NMR (1H, 13C, 2D), HRMS, and optical rotation to determine novel structure.
Visualizations
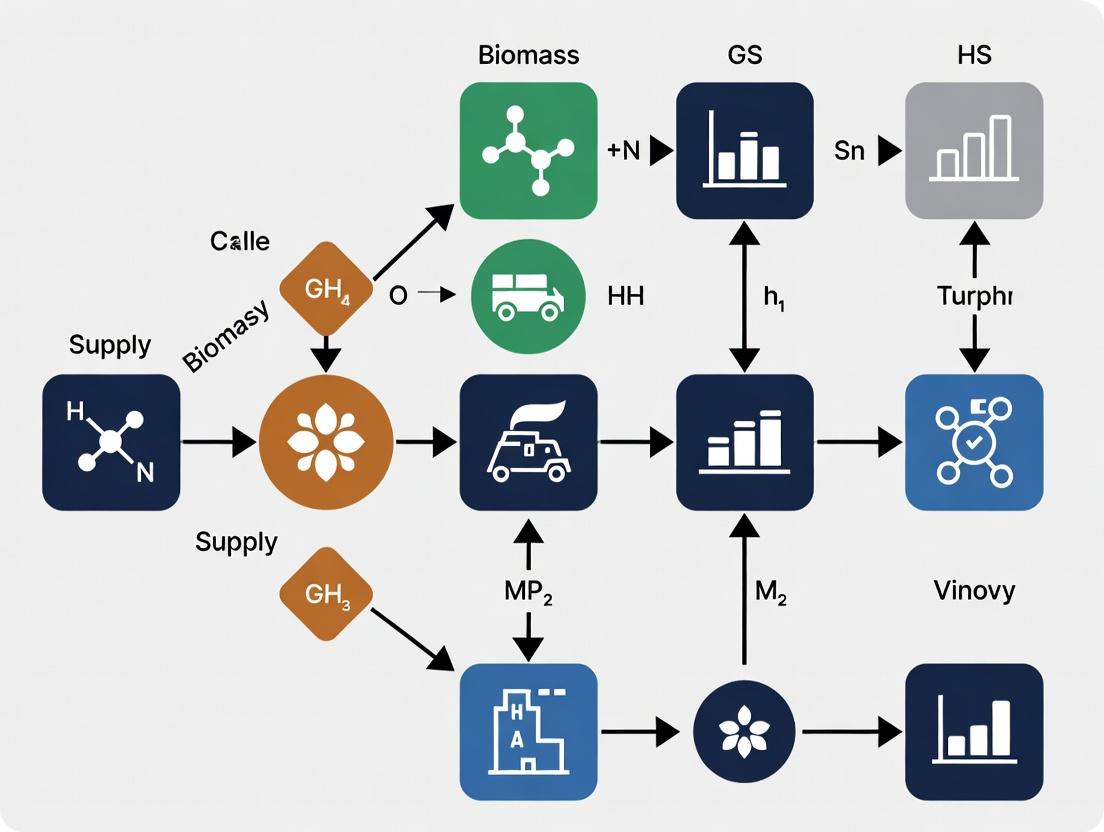
Title: GIS-LP Biomass Supply Chain Workflow
Title: Bioactivity-Guided Fractionation Protocol
The Scientist's Toolkit: Research Reagent Solutions
| Item | Function in Discovery Pipeline |
|---|---|
| Solid Phase Extraction (SPE) Cartridges (C18, Diol, Ion-Exchange) | Rapid clean-up of crude extracts to remove tannins, chlorophyll, or salts that interfere with assays and chromatography. |
| LC-MS Grade Solvents (MeCN, MeOH, H2O + modifiers) | Essential for high-resolution metabolomic profiling and preparative HPLC to ensure reproducibility and prevent system contamination. |
| Deuterated NMR Solvents (CDCl3, DMSO-d6, CD3OD) | Required for structure elucidation of novel compounds by 1D and 2D NMR spectroscopy. |
| Cell-Based Assay Kits (e.g., MTT, Caspase-Glo, Luciferase Reporter) | Standardized reagents for high-throughput screening of fractions for cytotoxicity, apoptosis, or pathway-specific bioactivity. |
| Sorbents for Column Chromatography (SiO2, C18, Sephadex LH-20) | Core media for fractionating complex natural product mixtures based on polarity or size. |
| Cryopreservation Agents (DMSO, Glycerol) | For long-term storage of unique microbial strains or plant cell lines producing bioactive compounds. |
Application Notes & Protocols
Note 1: GIS-LP Framework for Seasonal Biomass Availability Modeling
Objective: To integrate temporal GIS data with linear programming (LP) for optimizing harvest schedules and facility operations against seasonal biomass yield fluctuations.
Quantitative Data Summary: Seasonal Yield Variation of Common Feedstocks
| Feedstock Type | Geographic Region | Peak Yield Month | Yield (dry ton/ha) | Low Yield Month | Yield (dry ton/ha) | Annual Variance (%) | Data Source (Year) |
|---|---|---|---|---|---|---|---|
| Miscanthus | Midwest US | November | 28.5 | April | 2.1 | 92.6 | DOE BETO (2023) |
| Switchgrass | Southern US | October | 18.7 | March | 3.4 | 81.8 | USDA NASS (2024) |
| Corn Stover | Global | October | 5.6 | January | 0.5 | 91.1 | FAO STAT (2023) |
| Pine Residue | Southeast US | Year-Round | 2.1 (avg/month) | Year-Round | 2.1 (avg/month) | <5.0 | Forest Service (2023) |
Protocol 1.1: Spatio-Temporal Biomass Inventory Mapping
- Data Acquisition: Source multi-temporal (monthly) NDVI (Normalized Difference Vegetation Index) layers from Sentinel-2 or Landsat 8/9 via Google Earth Engine API.
- Yield Calibration: Establish region-specific regression models correlating NDVI values with ground-truthed dry biomass yield data (see Table 1).
- GIS Raster Processing: Apply the regression model to each monthly NDVI composite to generate a time-series of predicted yield rasters (GeoTIFF format).
- Availability Calculation: For each candidate bio-refinery location (shapefile), use Zonal Statistics to compute total available biomass (tons) within a user-defined radius (e.g., 80 km) for each month.
- LP Input Generation: Export monthly availability totals as the
Supply_tparameter for the LP model, wheretrepresents each time period (month).
Note 2: Protocols for Quality Parameter Integration into GIS-LP Models
Objective: To incorporate biomass quality attributes (e.g., moisture, carbohydrate content, contaminants) as constraints or penalty functions in supply chain optimization.
Quantitative Data Summary: Key Quality Metrics and Impact
| Quality Parameter | Typical Range | Impact on Processing | Target for Bioconversion | Test Method (ASTM/ISO) |
|---|---|---|---|---|
| Moisture Content | 15% - 50% (harvest) | Transportation cost, storage decay | <20% for stable storage | E871 / ISO 18134 |
| Glucan Content | 35% - 50% (dry basis) | Ethanol yield potential | Maximize | NREL LAP "Determination of Structural Carbohydrates" |
| Ash Content | 1% - 10% (dry basis) | Catalyst poisoning, slagging | Minimize | E1755 / ISO 18122 |
| Inorganics (K, Cl) | Variable ppm | Equipment corrosion | <0.1% total | ICP-MS Analysis |
Protocol 2.1: Geospatial Quality-Based Tiering of Feedstock
- Sampling Campaign: Design a stratified random sampling plan based on soil type, crop variety, and harvest practice GIS layers.
- Lab Analysis: Perform compositional analysis (following NREL Laboratory Analytical Procedures) on collected samples for key parameters (Glucan, Xylan, Lignin, Ash).
- Spatial Interpolation: Use Geostatistical Kriging in ArcGIS or QGIS to interpolate lab results, creating continuous prediction surfaces for each quality parameter.
- Create Quality Tiers: Reclassify prediction rasters into 3 tiers (e.g., Premium, Standard, Discount) based on threshold values (e.g., Premium: Glucan >45%, Ash <3%).
- LP Model Integration: Formulate the LP objective function to maximize total glucan delivered or assign differential costs/prices to each tier to guide optimal sourcing.
Note 3: Sustainability Metric Assessment and Supply Chain Balancing
Objective: To quantify and constrain environmental impacts within the GIS-LP optimization framework to ensure sustainable sourcing.
Quantitative Data Summary: Comparative Life Cycle Inventory Data
| Impact Category | Corn Stover (per dry ton) | Switchgrass (per dry ton) | Forest Residues (per dry ton) | Unit | Source |
|---|---|---|---|---|---|
| GHG Emissions (Cradle-to-Gate) | 120 - 180 | 35 - 60 | 15 - 40 | kg CO2-eq. | GREET 2024 Model |
| Soil Organic Carbon Change | -0.2 to -0.5 | +0.1 to +0.5 | ~0 (if sustainably harvested) | ton C/ha/yr | Journal of Industrial Ecology (2023) |
| Water Consumption | 150 - 300 | 50 - 150 | 20 - 50 | Liters | Water Footprint Network (2023) |
| Biodiversity Impact Score (local) | Moderate-High | Low-Moderate | Low (if guidelines followed) | Unitless (0-10) | GLOBIO Database |
Protocol 3.1: Multi-Objective Optimization for Sustainability
- Spatial Impact Modeling: Using GIS, calculate transport emissions (g CO2/ton-km) for all possible routes from supply locations to facilities. Overlay soil erosion risk maps to assign a sustainability score to each procurement zone.
- Define LP Objectives:
- Objective 1 (Cost): Minimize Total Cost = (Harvest + Transport + Storage + Preprocessing Cost).
- Objective 2 (Emissions): Minimize Total GHG = (Field Emissions + Transport Emissions).
- Apply Constraint Method: Set the emissions objective as a constraint (
Total GHG < Max_Threshold). Iteratively adjust the threshold and solve for cost minimization to generate a Pareto-optimal frontier. - Sensitivity Analysis: Run the model with varying carbon price scenarios ($/ton CO2-eq) to evaluate the economic resilience of the optimal supply chain design.
Mandatory Visualizations
The Scientist's Toolkit: Research Reagent & Software Solutions
| Item Name | Type | Function in Biomass SC Research | Example Vendor/Software |
|---|---|---|---|
| NREL LAP Suite | Analytical Protocols | Standardized methods for biomass composition (carbohydrates, lignin, ash), crucial for quality parameterization. | National Renewable Energy Lab |
| ANSI/ASAE S358.3 | Measurement Standard | Defines standard method for moisture content determination, ensuring data consistency. | ASABE Standards |
| GREET Model | Software Tool | Life cycle analysis (LCA) model to calculate GHG and energy impacts for sustainability constraints. | Argonne National Laboratory |
| Google Earth Engine | Cloud Platform | Enables large-scale, multi-temporal geospatial analysis (e.g., NDVI trends) without local compute burden. | |
| CPLEX / Gurobi | Solver Software | High-performance optimization engines for solving large-scale LP/MILP supply chain models. | IBM, Gurobi Optimization |
| QGIS with ORS Toolbox | GIS Software | Open-source GIS with routing plugins to calculate accurate transport distances/times for network modeling. | QGIS Development Team |
| ICP-MS Standard Kits | Lab Reagents | Certified standard solutions for calibrating instruments to measure inorganic contaminants (K, Cl, S) in biomass. | Merck, Agilent |
Application Notes
Within the context of a thesis on GIS-integrated linear programming (LP) for biomass supply chain optimization, these technologies serve as the foundational computational engine and spatial data framework. Their integration enables the transition from descriptive spatial analysis to prescriptive, optimized decision-making.
Table 1: Core Function Synergy in Biomass Supply Chain Research
| Technology | Primary Role in Supply Chain Research | Key Output for Integration |
|---|---|---|
| Geographic Information Systems (GIS) | Spatial data management, analysis, and visualization. Quantifies geographic variables: biomass yield, land cover, transport networks, facility locations. | Georeferenced data layers (rasters/vectors). Cost surfaces for transportation. Spatial constraints and parameters for the LP model. |
| Linear Programming (LP) | Mathematical optimization of a linear objective function subject to linear constraints. Allocates resources and flows to minimize cost or maximize profit. | Optimal biomass flow from collection points to biorefineries. Optimal facility locations and capacities. Shadow prices indicating constraint sensitivity. |
| Integrated GIS-LP Framework | Embeds spatial reality into the optimization model and projects optimization results back onto the map for interpretation and validation. | Geographically explicit optimal supply chain design. Scenario maps comparing different policy or market conditions. |
Table 2: Representative Quantitative Parameters from Recent Studies (2022-2024)
| Parameter Category | Typical Data Range / Value | Source (Spatial or Model Input) |
|---|---|---|
| Biomass Yield | 2.5 - 10.0 dry tons/acre/year (herbaceous crops) | GIS: Remote sensing, agricultural census data. |
| Collection & Pre-processing Cost | $20 - $65 per dry ton | GIS: Proximity analysis, LP: Cost function variable. |
| Transportation Cost | $0.15 - $0.35 per ton/mile | GIS: Network analysis creates cost surface. |
| Biorefinery Capacity | 500 - 2,000 dry tons/day | LP: Model constraint (upper/lower bound). |
| Model Solve Time (Medium-Scale) | < 5 minutes (for ~10^5 variables) | LP: Solver performance (e.g., Gurobi, CPLEX). |
Experimental Protocols
Protocol 1: GIS-Based Biomass Resource Assessment and Cost Surface Generation
- Objective: To create spatially explicit feedstock supply curves and transportation cost layers for the LP model.
- Materials: GIS software (e.g., ArcGIS Pro, QGIS), land use/land cover data, soil productivity data, road network data, agricultural parcel data.
- Procedure:
- Data Acquisition & Preprocessing: Acquire vector layers for agricultural fields, forests, or waste sources. Acquire raster data for yield factors (e.g., NDVI, soil index). Reproject all data to a consistent coordinate system.
- Biomass Potential Calculation: Using the Raster Calculator, compute spatially variable biomass yield:
Yield (tons/ha) = Base Yield * Soil Factor * Management Factor. Zonal statistics are used to summarize total available biomass per administrative or collection zone. - Collection Cost Modeling: Assign a fixed collection cost per ton, potentially varying by land cover type (e.g., forest vs. farmland).
- Transport Cost Surface Creation:
- Classify road networks by type (highway, rural) and assign speed/cost attributes.
- Use Cost-Distance or Network Analyst tools to calculate the cumulative cost (in $/ton) from every biomass source pixel to the nearest potential facility location, incorporating road costs and off-road transport penalties.
- Output Generation: Export two key raster layers: 1) Available Biomass (tons/pixel), and 2) Total Delivered Cost to Nearest Facility ($/ton). Aggregate pixel-level data to predefined "supply nodes" for the LP model.
Protocol 2: Formulating and Solving the Linear Programming Supply Chain Model
- Objective: To determine the optimal flow of biomass from supply nodes to candidate biorefinery locations to minimize total system cost.
- Materials: Optimization software (e.g., Python/PuLP, GAMS, MATLAB), GIS-derived parameter tables, LP solver (e.g., Gurobi, CBC).
- Procedure:
- Index and Parameter Definition:
- Let
i ∈ Ibe the set of biomass supply nodes (from Protocol 1). - Let
j ∈ Jbe the set of candidate biorefinery locations. - Define parameters:
S_i= Available biomass at node i (tons).C_ij= Total cost to harvest, pre-process, and transport biomass from i to j ($/ton). (Derived from GIS cost surface).D_j= Demand/capacity of biorefinery at j (tons).F_j= Fixed cost to establish a biorefinery at j ($).
- Let
- Variable Definition:
x_ij= Continuous, non-negative flow of biomass from i to j (tons).y_j= Binary variable (0 or 1) indicating if biorefinery j is built.
- Objective Function: Minimize Total Cost = Σi Σj (Cij * xij) + Σj (Fj * yj).
- Constraint Formulation:
- Supply Constraint: Σj xij ≤ Si, for all i. (Cannot exceed available biomass).
- Demand Constraint: Σi xij = Dj * yj, for all j. (If built, meet exact capacity; if not, no flow).
- Logical Flow Constraint: xij ≤ M * yj, for all i, j. (M is a large number; flow only to built facilities).
- Model Execution & Analysis: Solve the Mixed-Integer LP (MILP) model using a solver. Extract results: optimal flows
x_ij*, facility locationsy_j*, and dual prices (shadow costs) of binding constraints to inform spatial policy.
- Index and Parameter Definition:
Mandatory Visualizations
Integration of GIS and LP for Biomass Supply Chain Optimization
Core LP Model Structure for Facility Location
The Scientist's Toolkit
Table 3: Key Research Reagent Solutions for GIS-LP Biomass Research
| Tool/Reagent | Category | Function in Research |
|---|---|---|
| QGIS / ArcGIS Pro | GIS Software | Open-source/commercial platform for spatial data manipulation, analysis, and map production. Essential for creating model inputs. |
| Python (geopandas, rasterio) | Programming Library | Enables automation of GIS workflows and data pipeline construction, linking spatial analysis to optimization models. |
| PuLP / Pyomo | Optimization Modeling | Python-based modeling frameworks for formulating LP/MILP problems in a code-native environment. |
| Gurobi / CPLEX | Mathematical Solver | High-performance commercial solvers that efficiently find optimal solutions to large-scale LP/MILP problems. |
| Sentinel-2 / Landsat Imagery | Remote Sensing Data | Source for calculating vegetation indices (NDVI) to estimate biomass productivity spatially and temporally. |
| OpenStreetMap / TIGER | Network Data | Freely available road network data used to build transportation cost models and calculate logistics distances. |
1. Introduction and Context within GIS-Integrated Linear Programming Biomass Supply Chain Research The design of a biomass supply chain for pharmaceutical applications, such as sourcing plant-derived bioactive precursors, is a multi-objective optimization (MOO) problem. Within a GIS-Linear Programming (LP) or Mixed-Integer Linear Programming (MILP) framework, the mathematical objective function is the critical nexus where competing priorities are quantified and balanced. This application note details the protocol for defining this optimization goal, translating the strategic imperatives of cost, yield, sustainability, and risk into a form compatible with GIS-integrated LP models for biomass research.
2. Core Optimization Objectives: Quantitative Data Summary The primary objectives are defined, and typical quantitative metrics are summarized in Table 1.
Table 1: Core Optimization Objectives and Their Quantitative Metrics
| Objective | Primary Metric | Typical Unit | GIS-LP Model Variable | Desired Direction |
|---|---|---|---|---|
| Economic (Cost) | Total System Cost | $/kg of extracted compound | Sum of harvest, transport, pre-processing, storage costs | Minimize |
| Operational (Yield) | Compound Concentration | mg/g dry biomass | Yield coefficient per biomass type and location | Maximize |
| Environmental (Sustainability) | Lifecycle GHG Emissions | kg CO₂-eq/kg compound | Emission factor per supply chain activity | Minimize |
| Risk (Supply Security) | Supply Variance / Resilience Index | Unitless (0-1 scale) | Metric based on supplier reliability, climate disruption probability | Maximize |
3. Experimental Protocol for Parameterizing Objective Functions This protocol outlines steps to gather data for formulating the weighted multi-objective function.
Protocol 1: GIS-LP Objective Function Parameterization Objective: To collect and calculate the necessary coefficients for a weighted-sum objective function: Minimize Z = w₁(Cost) + w₂(-Yield) + w₃(Sustainability) + w₄(-Risk), where wᵢ are stakeholder-determined weights. Materials: GIS software (e.g., ArcGIS, QGIS), LP solver (e.g., GLPK, CPLEX), biomass field samples, lab analytical equipment. Procedure:
- Cost Factor Calibration:
- Use GIS to calculate transport distances from potential feedstock polygons (e.g., farm plots, wild harvest zones) to processing facilities.
- Integrate regional cost data ($/tonne-km for transport, $/hr for harvest).
- The LP cost variable Cᵢⱼ for biomass from source i to facility j is: Cᵢⱼ = (Harvest Costᵢ + (Distanceᵢⱼ × Transport Rate)) / Biomass Densityᵢ.
- Yield Factor Determination:
- Conduct phytochemical analysis on biomass samples from distinct GIS-located sources.
- Protocol 1a: HPLC Analysis for Target Compound Yield.
- Extract dried, powdered biomass using a standardized solvent (e.g., 80% methanol).
- Separate compounds via High-Performance Liquid Chromatography (HPLC) with a C18 column.
- Quantify target compound concentration (mg/g) against a validated standard curve.
- The yield coefficient Yᵢ is assigned to each biomass source polygon i in the GIS database.
- Sustainability Metric Integration:
- Assign lifecycle emission factors (kg CO₂-eq/kg biomass) to each operation (e.g., diesel harvesters, refrigerated transport).
- In the LP model, the sustainability objective is the sum of emissions from selected supply chain activities.
- Risk Index Quantification:
- For each supply zone i, compile historical data on yield stability (coefficient of variation) and climate disruption probability (e.g., drought flood risk from GIS layers).
- Calculate a normalized Resilience Index Rᵢ (0=high risk, 1=low risk).
- Multi-Objective Integration:
- Normalize all objective metrics to a common dimensionless scale (e.g., 0-1) using min-max scaling.
- Conduct a stakeholder analysis (e.g., Analytic Hierarchy Process) to determine weight sets (w₁, w₂, w₃, w₄) reflecting different strategic priorities (e.g., cost-driven vs. sustainability-driven).
- Solve the LP model iteratively with different weight sets to generate a Pareto-optimal frontier.
4. Visualization of the Multi-Objective Optimization Framework
Diagram 1: GIS-LP Multi-Objective Optimization Workflow (100 chars)
5. The Scientist's Toolkit: Key Research Reagent Solutions Table 2: Essential Materials for Biomass Supply Chain Optimization Research
| Item | Function in Research |
|---|---|
| GIS Software (e.g., QGIS, ArcGIS Pro) | Spatial analysis, network analysis for transport routing, and visual mapping of biomass sources and infrastructure. |
| LP/MILP Solver (e.g., Gurobi, CPLEX, open-source GLPK) | Computational engine to solve the mathematical optimization model and find cost-minimizing or profit-maximizing solutions. |
| HPLC System with PDA/UV Detector | Gold-standard for quantifying the concentration of the target bioactive compound in heterogeneous biomass samples. |
| Chemical Standards (Certified Reference Materials) | Essential for creating calibration curves to accurately identify and quantify compounds during HPLC analysis. |
| Life Cycle Assessment (LCA) Database (e.g., Ecoinvent) | Provides standardized emission factors for calculating the sustainability objective (e.g., GHG emissions per unit activity). |
| Climate Risk Datasets (e.g., IPCC reports, local weather models) | Used to parameterize the risk objective, quantifying probabilities of supply disruption for resilience modeling. |
Building Your Model: A Step-by-Step GIS-LP Framework for Biomass Logistics
Within a Geographic Information System (GIS)-integrated linear programming (LP) framework for biomass supply chain optimization, the formulation of a precise mathematical model is critical. This step translates the geographically explicit data into a solvable optimization problem, enabling researchers and bio-economy professionals to make informed decisions regarding feedstock procurement, logistics, and facility placement for applications such as bio-drug precursor production.
Decision Variables
Decision variables represent the choices under the control of the decision-maker. In a biomass supply chain, these typically quantify material flows and facility utilization.
Table 1: Primary Decision Variables in a Biomass Supply Chain LP Model
| Variable Symbol | Description | Units | Example (Indexed Form) |
|---|---|---|---|
| ( X_{ijt} ) | Quantity of biomass transported from supply zone ( i ) to processing facility ( j ) in period ( t ). | ton (dry) | ( X_{i=5, j=2, t=3} = 150 ) |
| ( Y_{jkt} ) | Quantity of processed biomass (e.g., bio-oil, pellets) transported from facility ( j ) to demand center ( k ) in period ( t ). | ton, liter | ( Y_{j=2, k=1, t=3} = 120 ) |
| ( Z_j ) | Binary variable for the establishment (1) or non-establishment (0) of a processing facility at candidate location ( j ). | 0 or 1 | ( Z_{j=4} = 1 ) |
| ( U_{jt} ) | Utilization rate of processing capacity at facility ( j ) in period ( t ). | Ratio (0-1) | ( U_{j=2, t=3} = 0.85 ) |
| ( H_{it} ) | Quantity of biomass harvested in supply zone ( i ) in period ( t ). | ton (dry) | ( H_{i=5, t=3} = 200 ) |
Objective Function
The objective function defines the goal of the optimization. For a cost-minimizing biomass supply chain, it aggregates all relevant costs.
General Form: [ \text{Minimize } TotalCost = \text{Harvesting Cost} + \text{Transportation Cost} + \text{Facility Cost} ]
Mathematical Formulation: [ \text{Min } Z = \sum{t} \sum{i} (C^{h}{i} \cdot H{it}) + \sum{t} \sum{i} \sum{j} (C^{t}{ij} \cdot d{ij} \cdot X{ijt}) + \sum{j} (C^{f}{j} \cdot Zj) + \sum{t} \sum{j} (C^{p}{j} \cdot \sum{i} X{ijt}) ]
Where:
- ( C^{h}_{i} ): Harvesting cost per unit biomass at zone ( i ) ($/ton).
- ( C^{t}_{ij} ): Transportation cost per unit biomass per unit distance from ( i ) to ( j ) ($/ton/km).
- ( d_{ij} ): Distance from supply zone ( i ) to facility ( j ) (km), typically derived from GIS network analysis.
- ( C^{f}_{j} ): Fixed annualized cost of establishing facility at location ( j ) ($).
- ( C^{p}_{j} ): Processing cost per unit biomass at facility ( j ) ($/ton).
Constraints
Constraints model the physical, economic, and policy limitations of the supply chain system.
Table 2: Core Constraint Sets in a Biomass Supply Chain LP Model
| Constraint Category | Mathematical Formulation | Description |
|---|---|---|
| Supply Availability | ( \sum{j} X{ijt} \leq A_{it} \cdot \eta ) for all ( i, t ) | Biomass shipped from a zone cannot exceed its available yield ( A_{it} ) adjusted by recovery rate ( \eta ). |
| Demand Fulfillment | ( \sum{j} Y{jkt} \geq D_{kt} ) for all ( k, t ) | Demand at center ( k ) in period ( t ) must be met. |
| Mass Balance | ( \sum{i} X{ijt} \cdot \rho = \sum{k} Y{jkt} ) for all ( j, t ) | Mass flow into a facility equals flow out, adjusted by conversion efficiency ( \rho ). |
| Facility Capacity | ( \sum{i} X{ijt} \leq CAPj \cdot Zj ) for all ( j, t ) | Biomass processed cannot exceed the capacity of an established facility. |
| Non-negativity & Binary | ( X{ijt}, Y{jkt}, H{it} \geq 0; Zj \in {0,1} ) | Physical flows are non-negative; facility establishment is binary. |
| Spatial (GIS-derived) | ( X{ijt} = 0 ) if ( d{ij} > d_{max} ) | Prevents unrealistic long-distance transport, based on GIS-calculated network distances. |
Experimental Protocol: GIS-LP Integration Workflow
Protocol Title: Integrated Geospatial and Linear Programming Analysis for Optimal Biomass Facility Siting.
Objective: To determine the optimal locations and capacities for biomass preprocessing depots to minimize total system cost.
Materials & Software:
- GIS Software (e.g., QGIS, ArcGIS Pro)
- Network Dataset (Roads, railways)
- Biomass Yield Raster Data
- LP Solver (e.g., CPLEX, Gurobi, or open-source alternatives like PuLP in Python)
- Python/R Scripting Environment for integration.
Procedure:
- Data Preparation (GIS):
- Delineate biomass supply zones (polygons) from land use/cover data.
- Calculate annualized biomass availability (( A_{it} )) per zone using yield maps and sustainability factors.
- Identify candidate facility locations (points) based on land zoning and infrastructure proximity.
- Generate a cost-distance matrix (( C^{t}{ij} \cdot d{ij} )) using Network Analyst tools, modeling travel cost between all supply zones and candidate sites.
- Parameterization:
- Extract tabular data from GIS: ( A{it} ), cost-distance matrix, ( D{kt} ).
- Assign economic parameters: ( C^{h}{i} ), ( C^{f}{j} ), ( C^{p}_{j} ), ( \eta ), ( \rho ).
- Model Formulation:
- Define decision variables, objective function, and constraints as specified in Sections 2-4 within the solver/scripting environment.
- Import GIS-derived parameters as coefficients.
- Model Execution & Validation:
- Solve the LP/MILP (Mixed-Integer LP if ( Z_j ) is binary) using the chosen solver.
- Perform sensitivity analysis on key parameters (e.g., biomass price, demand).
- Results Visualization (GIS):
- Map the optimal biomass flows (( X_{ijt} )) as line vectors.
- Map selected facility locations (( Zj = 1 )) and their utilization rates (( U{jt} )).
- Create charts showing cost breakdown and spatial distribution of resource utilization.
Visualization: GIS-LP Integration Workflow
Title: GIS-LP Model Integration Workflow
The Scientist's Toolkit
Table 3: Essential Research Reagent Solutions for Biomass Supply Chain Modeling
| Item / Solution | Function in Research | Example in Protocol |
|---|---|---|
| GIS Software (QGIS/ArcGIS) | Platform for spatial data management, analysis, and visualization of biomass resources and network infrastructure. | Used in Protocol Step 1 for zone delineation and cost-distance calculation. |
| Network Analyst Extension | Tool within GIS to model realistic transportation networks and calculate least-cost paths, crucial for accurate ( d_{ij} ). | Generates the cost-distance matrix for the objective function. |
Python PuLP / pyomo Library |
Open-source modeling languages for formulating LP/MILP problems and connecting to solvers. | Used in Protocol Step 3 to code the mathematical model defined in Sections 2-4. |
| Commercial Solver (Gurobi/CPLEX) | High-performance optimization engines for solving large-scale LP/MILP problems efficiently. | Called by the modeling library in Protocol Step 4 to find the optimal solution. |
| Geospatial Database (PostGIS) | Database system for storing and querying large, complex spatial datasets (e.g., multi-year yield data for all supply zones). | Serves as the centralized data source for parameters ( A_{it} ) and spatial features. |
| Sustainability Coefficients (( \eta, \rho )) | Numeric factors derived from agronomic or processing experiments that adjust theoretical biomass availability and conversion rates to practical, sustainable levels. | Applied in Supply Availability and Mass Balance constraints to ensure model realism. |
Application Notes
The integration of Geographic Information Systems (GIS) with Linear Programming (LP) optimization models is a critical step in designing efficient biomass supply chains for bioenergy and biochemical production. This conversion process transforms spatially explicit data into quantifiable parameters that drive strategic decisions regarding facility location, biomass allocation, and logistics, directly impacting the economic viability and environmental footprint of biorefineries.
Core Quantitative Data Parameters
The following table summarizes key spatial data layers and their derived LP model parameters essential for biomass supply chain modeling.
Table 1: GIS Data Layers and Corresponding LP Model Parameters
| GIS Data Layer/Category | Key Attributes | Derived LP Parameter | Typical Unit | Calculation Notes |
|---|---|---|---|---|
| Biomass Supply Points | Yield (dry ton/ha), Area (ha), Availability period | Supply capacity (S_i) | dry tons | Total yield per spatially defined parcel (e.g., county, field). |
| Candidate Facility Sites | Land cost, Proximity to infrastructure | Fixed establishment cost (F_j) | $ | Site-specific cost from spatial economic data. |
| Transportation Network | Road type, Speed limit, Toll cost, Distance | Unit transportation cost (C_ij) | $/dry-ton/km or $/dry-ton | Cost based on route-specific distance, road class, and vehicle type. |
| Spatial Distance / Route | Euclidean or Network distance | Distance (D_ij) | km or miles | Calculated from centroid of supply area to facility site. |
| Demand / Conversion Points | Technology type, Capacity, Co-product demand | Demand requirement (D_k) | dry tons | Target biomass input for biorefinery or drug precursor production. |
| Environmental Constraints | Protected areas, Slope, Water bodies | Binary constraint coefficient (δ_ij) | Unitless | 0 if route/land use is prohibited, 1 otherwise. |
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Software and Data Tools for GIS-LP Integration
| Tool / Resource | Category | Primary Function in GIS-LP Bridging |
|---|---|---|
| ArcGIS Pro / QGIS | GIS Software | Platform for spatial analysis, geoprocessing, and visualization of biomass sources, infrastructure, and constraints. |
| Network Analyst Extension (ArcGIS) | GIS Toolset | Calculates origin-destination cost matrices using real road networks, accounting for travel time, distance, and barriers. |
| Python (geopandas, pandas, osmnx) | Programming Language | Automates data extraction, cleaning, spatial joins, and cost matrix calculation via scripting. Essential for reproducible workflows. |
| OpenStreetMap (OSM) | Spatial Data Source | Provides free, globally available road network data for routing and distance calculations. |
| USDA NASS Cropland Data Layer | Thematic Raster Data | Provides high-resolution, crop-specific land cover data for estimating biomass availability and location. |
| Linear Programming Solver (Gurobi, CPLEX, PuLP) | Optimization Engine | Receives the cost matrices and parameters from GIS to solve the supply chain optimization model. |
| Google Earth Engine | Cloud Computing Platform | Useful for large-scale remote sensing analysis to estimate biomass yields over time. |
Experimental Protocols
Protocol 1: Generating a Transportation Cost Matrix from Spatial Data
Objective: To compute a comprehensive origin-destination cost matrix between biomass supply centroids and candidate biorefinery locations for input into an LP model.
Materials & Software:
- GIS Software (QGIS 3.34 or ArcGIS Pro 3.2)
- Road network data (shapefile or OpenStreetMap
.osmformat) - Point shapefiles for supply centroids and facility sites.
- Python environment with
geopandas,networkx,osmnx, andpandaslibraries.
Methodology:
Data Preparation: a. Load supply area polygons (e.g., county boundaries, farm parcels). Calculate the geometric centroid for each polygon to represent the supply origin point (i). b. Load point layer for all candidate facility locations (j). c. Download or load a routable road network for the study region. Ensure network topology is correct (nodes, edges, connectivity).
Network Analysis & Cost Calculation: a. Snap Points to Network: Use the GIS
snapfunction to project each supply centroid and facility point onto the nearest node or edge of the road network. b. Calculate Cost Attribute: Create a network cost attribute (e.g., travel time in hours) based on road class and length. For simplicity, cost can be distance (km). c. Run Origin-Destination Cost Matrix: Execute the network analysis tool (e.g.,OD Cost Matrixin ArcGIS orosmnx.distance.nearest_nodesandnetworkx.shortest_path_lengthin Python). Specify origins as supply points and destinations as facility points. d. The tool computes the least-cost path (shortest network distance) for all origin-destination (i, j) pairs.Derive Unit Transportation Cost: a. Export the resulting distance matrix (D_ij) to a
.csvfile. b. Apply a transportation cost formula using a scripting language. A standard approach is:C_ij = (α * D_ij + β) / ηwhere: *C_ij= Transportation cost from supply i to facility j ($/dry ton) *α= Variable cost coefficient ($/km/truck) *D_ij= Network distance (km) *β= Fixed loading/unloading cost ($/ton) *η= Average truck payload (dry ton/truck) c. Populate the finalC_ijcost matrix table for the LP model.
Deliverable: A n x m matrix (n supplies, m facilities) of unit transportation costs (C_ij).
Protocol 2: Incorporating Spatial Constraints into LP Model Formulation
Objective: To integrate spatially derived exclusionary constraints into the LP model structure.
Methodology:
- Constraint Identification: Within the GIS, identify zones where biomass procurement or transportation is infeasible (e.g., protected national parks, urban areas, steep slopes >20%).
- Spatial Overlay Analysis: a. Perform an intersect operation between supply area polygons and the "exclusion" constraint polygons. b. For transportation, run a network analysis to identify routes crossing constrained areas, or create a cost raster where traversing constrained cells incurs an extremely high cost.
- Parameter Encoding for LP:
a. For supply constraints: If a supply polygon i overlaps an exclusion zone, set its maximum supply parameter
S_i_max = 0in the LP data input. b. For transportation constraints: If the optimal path between i and j traverses a forbidden zone, adjust the model by either: * Setting the binary variableX_ij(for route selection) to 0, or * Artificially inflating the correspondingC_ijto a very high value (Big M method) to make the route non-optimal. - Model Integration: Directly write the modified supply capacities
S_iand the adjusted cost matrixC_ijinto the LP model's data file (e.g.,.datfile for AMPL, or within Python'sPuLPorpyomoscript).
Mandatory Visualizations
Title: GIS-LP Integration Workflow for Biomass Supply Chains
Title: Transportation Cost Matrix Calculation Process
Within a GIS-integrated Linear Programming (LP) framework for biomass supply chain optimization, the implementation phase translates the mathematical model into an operational decision-support tool. This step is critical for researchers and bio-economy professionals aiming to minimize logistics costs, maximize resource utilization, and assess sustainability trade-offs. The selection of software tools dictates the model's scalability, integration capabilities, and analytical rigor.
Comparative Analysis of Primary Implementation Platforms
The following table summarizes the core characteristics, advantages, and data requirements for two predominant GIS-LP integration paradigms.
Table 1: Comparison of GIS-LP Integration Tool Suites
| Feature/Capability | ArcGIS Pro with Python/Pyomo | GRASS GIS with R (lpSolve, Rglpk) |
|---|---|---|
| Primary GIS Environment | Commercial, integrated desktop suite. | Open-source, modular command-line/ GUI (QGIS). |
| Optimization Backend | Pyomo (Python-based, supports multiple solvers: CBC, GLPK, Gurobi). | R packages (e.g., lpSolve, Rglpk, ompr). |
| Spatial Data Handling | Native geodatabase support. Direct geometry object manipulation via arcpy. |
Integrated raster/vector engine via sp, sf, raster packages in R. |
| Model Integration Style | Tight coupling: Spatial analysis and LP solve can be scripted within a single ArcPy environment. | Loose coupling: Data exchanged between GRASS modules and R scripts via common file formats or direct pipes. |
| Typical Workflow | 1. Build network (Location-Allocation).2. Calculate cost rasters.3. Extract attributes to CSV.4. Formulate & solve Pyomo model.5. Map results. | 1. Process rasters/vectors in GRASS.2. Export matrices to R.3. Formulate & solve LP in R.4. Import solution for visualization in GRASS/QGIS. |
| Key Strength | Seamless workflow for proprietary data stacks; advanced network analyst. | High reproducibility; cost-free; extensive statistical post-processing in R. |
| Performance Consideration | Large rasters can slow preprocessing. Solver choice impacts speed. | Memory-bound with very large spatial LP matrices; efficient scripting is crucial. |
| Primary Data Inputs | Feedstock yield rasters, road network vectors, facility location points, cost parameters. | Same as ArcGIS Pro, but commonly in open formats (GeoTIFF, Shapefile, GeoPackage). |
| Optimal For | Enterprise environments with existing ESRI licenses; complex spatial logistics. | Academic and open-source research; projects requiring advanced statistical validation. |
Experimental Protocols for Biomass Supply Chain LP Implementation
Protocol A: ArcGIS Pro and Pyomo Integration for Multi-Feedstock Sourcing
Objective: To determine the least-cost sourcing mix from multiple biomass types (e.g., agricultural residue, energy crops) for a biorefinery, accounting for spatial variability in yield and transport cost.
Materials & Software:
- ArcGIS Pro (v3.2+)
- Python 3.9+ with libraries:
arcpy,pyomo,pandas,numpy - Solver: COIN-OR CBC (open-source) or Gurobi (commercial)
Procedure:
- Data Preparation (ArcGIS Pro):
- For each feedstock
i, convert yield maps (Mg/ha) to available biomass raster (Biomass_i). - Using the
Cost Distancetool, generate a transport cost raster (CostPerMg_i) for each feedstock, using road networks and terrain resistance. - Using
Zonal Statistics, aggregateBiomass_iand calculate averageCostPerMg_ifor each supply zonej(e.g., county parcels). Export to tablesupply_data.csv. - Export biorefinery demand and feedstock quality specs (e.g., moisture, ash content) to
demand_data.csv.
- For each feedstock
Pyomo Model Formulation (Python IDE):
- Read
supply_data.csvanddemand_data.csvinto Pandas DataFrames. - Instantiate a Concrete Model (
model = pyomo.ConcreteModel()). - Sets: Define sets for Feedstocks (
model.F) and Supply Zones (model.S). - Parameters: Define
model.availability[F,S],model.cost[F,S],model.demand[F]. - Variables: Define non-negative continuous variable
model.flow[F,S]representing biomass quantity shipped. - Objective: Minimize total cost:
sum(model.cost[f,s] * model.flow[f,s] for f in F for s in S). - Constraints:
- Supply limit:
sum(model.flow[f,s] for f in F) <= model.availability[f,s]. - Demand satisfaction:
sum(model.flow[f,s] for s in S) == model.demand[f].
- Supply limit:
- Solve using
SolverFactory('cbc').solve(model).
- Read
Solution Mapping (ArcGIS Pro):
- Join the optimized
model.flowvalues back to the spatial supply zone layer. - Symbolize zones based on allocated quantities to visualize the procurement landscape.
- Join the optimized
Protocol B: GRASS GIS and R Integration for Facility Location-Allocation
Objective: To identify optimal locations for 3 new preprocessing depots within a region to minimize total transport cost from supply fields to a central biorefinery.
Materials & Software:
- GRASS GIS (v8.3+)
- R (v4.3+) with packages:
sf,rgrass7,lpSolve,ggplot2 - QGIS for optional visualization
Procedure:
- Network Analysis (GRASS GIS):
- Import vector maps:
fields(source points with biomass tonnage),candidate_depots,biorefinery, androads. - Use
v.net.allpairsto compute shortest-path cost matrices between all fields, candidate depots, and the biorefinery. - Export the cost matrices to CSV files:
cost_fields_to_depots.csv,cost_depots_to_biorefinery.csv. - Export field biomass quantities as
supply.csv.
- Import vector maps:
Integer Linear Programming Model (R):
- Connect R to GRASS session using
rgrass7::initGRASS(). - Read cost matrices and supply data into R.
- Formulate a binary integer programming model:
- Binary Variables:
x_j= 1 if candidate depotjis selected. - Continuous Variables:
y_ij= flow from fieldito depotj;z_j= flow from depotjto biorefinery. - Objective: Minimize total transport cost (field->depot + depot->biorefinery).
- Constraints: Supply at fields, flow conservation at depots, exactly 3 depots selected (
sum(x_j) == 3).
- Binary Variables:
- Solve using
lpSolve::lp("min", objective.in, const.mat, const.dir, const.rhs, all.bin=TRUE).
- Connect R to GRASS session using
Results Visualization:
- Write the solution (selected depot IDs and flows) to a new table in GRASS.
- In GRASS or QGIS, visually highlight the chosen depots and illustrate the allocated supply flows using arrows or graduated symbols.
Visualizing the Implementation Workflow
Title: Dual-Path Workflow for GIS-LP Biomass Model Implementation
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Digital "Reagents" for GIS-LP Biomass Research
| Item Name | Function in the Experiment | Format/Type | Key Attributes |
|---|---|---|---|
| Feedstock Yield Raster | Quantifies biomass availability per unit area across the landscape. | GeoTIFF (.tif) | Resolution (e.g., 30m pixel); Units (Mg/ha/yr); Temporal validity. |
| Transport Cost Raster | Represents the generalized cost ($/Mg) to move biomass from any cell to a facility. | GeoTIFF (.tif) | Derived from road network, slope, travel speed; Critical for spatial LP. |
| Supply Zone Vector | Defines discrete spatial units for biomass aggregation (e.g., farms, counties). | Polygon Shapefile/GeoPackage | Unique ID field; Links spatial data to LP decision variables. |
| Linear Programming Solver | Computational engine that finds the optimal solution to the mathematical model. | Software Library (CBC, GLPK) | Speed, problem type support (MIP, NLP), license type (open/commercial). |
| Spatial-Analysis Script Library | Reusable code modules for cost-distance, zonal stats, and data conversion. | Python (.py) or R (.R) files | Promotes reproducibility and method standardization across experiments. |
| Parameter Configuration File | Stores all non-spatial model inputs (costs, demands, conversion factors). | YAML/JSON/CSV (.yml, .json, .csv) | Ensures experiment transparency and easy scenario modification. |
1.0 Application Notes
1.1 Thesis Context Integration This case study is framed within a doctoral thesis investigating the integration of Geographic Information Systems (GIS) with linear programming (LP) models to optimize biomass supply chains. The primary research gap addressed is the lack of spatially explicit, multi-objective optimization frameworks for rare, slow-growing, and geographically constrained medicinal plant species, such as Hoodia gordonii. The thesis posits that a GIS-integrated LP model can simultaneously minimize logistical cost and ecological impact while ensuring supply security for early-stage drug development.
1.2 Quantitative Data Summary
Table 1: Key Parameters for a Hypothetical Hoodia gordonii Supply Chain Model
| Parameter Category | Specific Parameter | Example Value / Range | Source / Justification |
|---|---|---|---|
| Plant Biology | Growth Cycle to Harvestable Maturity | 5-7 years | CITES NDF Assessment |
| Average Yield of Active Dry Biomass (ADB) | 0.5 kg ADB / plant | Cultivation trial literature | |
| Minimum Concentration of Active P57 Compound | 0.1% of ADB | Pharmacopoeia standards | |
| Spatial & Supply | Number of Potential Cultivation Sites (Polygons) | 15-25 | GIS analysis (soil, climate) |
| Distance from Sites to Processing Lab (Range) | 50 - 1200 km | Network analysis in GIS | |
| Annual Demand for Pre-clinical Trial Batch | 50 kg ADB | Sponsor requirement | |
| Economic | Cultivation Cost per Plant (Annualized) | $10 - $25 USD | Farmer surveys, agronomy models |
| Transportation Cost per km per kg ADB | $0.15 USD | Freight rate databases | |
| Processing Cost per kg ADB (Solvent Extraction) | $200 USD | Lab operational budgets | |
| Constraints | Maximum Sustainable Harvest per Site (Annual) | Site-specific (5-100 kg) | Ecological Carrying Capacity Model |
| Minimum Supply Reliability Target | 99% | Risk mitigation policy | |
| Carbon Emission Cap for Logistics | 500 kg CO2e | Corporate sustainability goal |
Table 2: LP Model Objective Function Components & Decision Variables
| Component | Variable Type | Description | Unit | |
|---|---|---|---|---|
| Objective 1: Min Cost | CultivateCost_i |
Continuous | Cost to grow biomass at site i | USD |
TransportCost_ij |
Continuous | Cost to transport biomass from site i to lab j | USD | |
| Objective 2: Min Ecological Impact | HarvestIntensity_i |
Continuous | Biomass harvested from site i as % of its carrying capacity | Dimensionless |
| Decision Variables | X_i |
Continuous | Amount of ADB (kg) to procure from cultivation site i | kg |
Y_ij |
Binary | Whether route from site i to lab j is used (1) or not (0) | 0/1 | |
| Constraints | Demand_j |
Parameter | Total ADB required at processing lab j | kg |
Capacity_i |
Parameter | Max sustainable harvest at site i | kg |
2.0 Experimental Protocols
2.1 Protocol: GIS Suitability Analysis for Potential Cultivation Sites Objective: To identify and characterize geographically discrete polygons as candidate source nodes for the supply network. Materials: QGIS or ArcGIS software, climate datasets (WorldClim), soil maps (FAO SoilGrids), land cover data (ESA CCI), species occurrence records (GBIF). Procedure:
- Data Layer Compilation: Import raster and vector layers for the study region (e.g., arid regions of Southern Africa) for key factors: precipitation, temperature, soil drainage, land use type, and existing protected areas.
- Constraint Masking: Apply binary masks to exclude legally protected areas, urban zones, and major water bodies. Reclassify remaining area as "potentially suitable."
- Factor Weighting & Overlay: Using Analytic Hierarchy Process (AHP) surveys with botanical experts, assign weights to each growth factor. Perform a Weighted Linear Combination (WLC) to create a continuous suitability index raster (0-1).
- Polygon Delineation: Convert high-suitability areas (>0.7) into discrete vector polygons. These represent potential cultivation sites
i. For each polygon, calculate and tabulate geospatial attributes: centroid coordinates, area (hectares), mean annual rainfall, and estimated ecological carrying capacity (see Protocol 2.2).
2.2 Protocol: Field-Based Estimation of Ecological Carrying Capacity (ECC)
Objective: To determine the maximum annual sustainable harvest biomass (Capacity_i) for a identified site polygon.
Materials: Quadrat frame (1m x 1m), GPS unit, soil core sampler, drying oven, scale.
Procedure:
- Stratified Random Sampling: Within the target polygon, define 3-5 strata based on minor variability in slope or vegetation density. In each stratum, randomly place 5 quadrats.
- Baseline Biomass & Density: For each mature Hoodia plant within a quadrat, record height and basal diameter. Destructively harvest a single, non-trial plant outside quadrats to establish an allometric equation (diameter vs. dry weight). Use this to estimate total standing biomass per quadrat. Count all juvenile plants (<5 years).
- Population Viability Metrics: In adjacent control areas, tag 50 individual plants for annual monitoring of growth rate, mortality, and recruitment.
- ECC Calculation: Using a modified Schaefer model:
ECC_i = (r * B_max * A) / 4, whereris the intrinsic growth rate from tagged plants,B_maxis the maximum estimated standing biomass per hectare from quadrat data, andAis the suitable area within the polygon in hectares. The result (kg/year) becomes the constraintCapacity_ifor that site in the LP model.
2.3 Protocol: Multi-Objective Linear Programming Model Formulation & Solving Objective: To generate Pareto-optimal supply network designs that balance cost and ecological impact. Materials: Python (PuLP or Pyomo library), GIS connectivity matrix, parameter tables. Procedure:
- Model Formulation:
- Decision Variables: Define as per Table 2.
- Objective Functions:
Z1 = Min( Σ_i (CultivateCost_i * X_i) + Σ_i Σ_j (TransportCost_ij * Distance_ij * X_i * Y_ij) )Z2 = Min( Σ_i ( (X_i / Capacity_i) * Weight_i ) )whereWeight_iis a biodiversity value index.
- Constraints:
- Demand Satisfaction:
Σ_i X_i >= Demand_j - Supply Limits:
X_i <= Capacity_i - Route Logic:
X_i <= M * Y_ij(Big-M constraint linking continuous and binary variables).
- Demand Satisfaction:
- ε-Constraint Solving: Solve
Z1as the primary objective, convertingZ2into a constraint (Z2 <= ε). Iteratively adjust ε to trace the Pareto frontier. - Solution Mapping: For each Pareto-optimal solution, map the selected sites (
Y_ij = 1) and their allocated flows (X_i) back into the GIS platform to visualize the optimal network geometry.
3.0 Mandatory Visualization
Diagram Title: GIS-LP Supply Chain Optimization Workflow
4.0 The Scientist's Toolkit
Table 3: Key Research Reagent Solutions & Essential Materials
| Item | Function in the Case Study |
|---|---|
| QGIS / ArcGIS Pro Software | Open-source/commercial GIS platform for spatial analysis, suitability modeling, and map creation. Essential for defining site polygons and calculating transport distances. |
| Python with PuLP/Pyomo | Programming language and libraries for formulating and solving the linear programming optimization model. Allows for automation and integration with GIS outputs. |
| WorldClim / SoilGrids Datasets | High-resolution global climate and soil data layers. Provide critical input variables for the ecological niche modeling and site suitability analysis. |
| GPS Unit & Quadrat Sampler | Field equipment for precise geolocation of sample points and standardized measurement of plant density and biomass within defined plots. |
| Allometric Equation Calibration Kit (Calipers, Drying Oven, Precision Scale) | Tools to establish a non-destructive method for estimating plant dry weight from field measurements (e.g., stem diameter), crucial for carrying capacity estimates. |
| ε-Constraint Optimization Algorithm | A multi-objective programming technique implemented in code to generate the set of non-dominated, Pareto-optimal solutions balancing cost and sustainability. |
Overcoming Real-World Hurdles: Data Gaps, Model Sensitivity, and Dynamic Adjustments
Within the thesis framework of GIS-integrated linear programming (LP) for biomass supply chain optimization, spatial data quality is the primary determinant of model fidelity. Incomplete or low-resolution data on feedstock locations, road networks, soil quality, and land use introduce significant uncertainty, leading to non-optimal or infeasible supply chain solutions. These pitfalls directly compromise the economic and environmental conclusions of the research, affecting downstream applications in bio-based drug precursor development.
Table 1: Characterizing Data Pitfalls in Biomass Supply Chain Models
| Pitfall Category | Typical Data Sources Affected | Quantifiable Impact on LP Model | Common Resolution (km² or %) |
|---|---|---|---|
| Spatial Gaps | Cadastral surveys, soil samples, yield maps | Creates infeasible procurement zones; underestimates transport cost. | Gaps of 5-15% of study area common. |
| Low Resolution | Remote sensing (Land cover), census data, digital elevation models (DEMs) | Over/under-estimation of biomass density by 20-40%. Aggregation error in route calculation. | Pixel sizes >30m for land cover; Admin boundaries >10km². |
| Attribute Missingness | Farmer surveys, facility capacity databases | Uncertainty in constraint coefficients (e.g., moisture content, capacity). | 10-30% missing attribute values per record. |
| Coordinate Inaccuracy | GPS point collections, historic parcel maps | Misalignment of source and network by >100m. Increases modeled transport distance error. | RMSE of 50-200m common for non-differential GPS. |
| Temporal Misalignment | Multi-year yield data, infrastructure maps | Use of non-contemporaneous data skews seasonal LP formulation. | Data age discrepancy of 3-5 years typical. |
Table 2: Consequences for Supply Chain Cost & Drug Development Timeline
| Data Issue | Impact on Minimum Transportation Cost (Modeled Variance) | Impact on Precursor Compound Sourcing Reliability | Potential Delay in Pre-clinical Material Securement |
|---|---|---|---|
| Low-Resolution Biomass Map | +15% to +25% | High risk of supply shortfall in critical regions. | 3-6 months for re-survey and re-modeling. |
| Incomplete Road Network | +10% to +30% | Route failure, inability to access high-potency zones. | 1-4 months for field validation and network correction. |
| Missing Soil Constraints | -5% to +10% (via yield overestimation) | Unanticipated quality degradation during storage/transport. | 2-5 months for quality remediation protocols. |
Experimental Protocols for Mitigating Spatial Data Pitfalls
Protocol 1: Gap-Filling and Spatial Interpolation for Biomass Yield Points
Objective: To generate a continuous biomass availability surface from incomplete point-sampled yield data.
Materials: Point shapefile of yields, covariate rasters (soil index, precipitation), GIS software (e.g., QGIS, ArcGIS Pro), R/Python with gstat/scipy libraries.
Procedure:
- Data Audit: Calculate and map the spatial autocorrelation (Moran's I) of point data to confirm interpolation appropriateness.
- Covariate Selection: Perform cross-correlation analysis between yield points and continuous covariate rasters (e.g., NDVI, soil organic carbon).
- Variogram Modeling: Model the spatial structure of the residuals using an exponential or spherical variogram.
- Interpolation: Execute regression kriging:
Yield = f(covariates) + kriged(residuals). - Validation: Use leave-one-out cross-validation. Report Root Mean Square Error (RMSE) and Mean Absolute Error (MAE). Only adopt surfaces with RMSE < 15% of mean yield.
Protocol 2: Multi-Resolution Data Fusion for Land Use Classification
Objective: To enhance the effective resolution of land cover classification for identifying marginal land suitable for biomass cultivation. Materials: Low-resolution Landsat/Sentinel-2 imagery (10-30m), high-resolution but incomplete aerial survey or UAV data (<1m), ground-truth polygons. Procedure:
- Co-registration: Precisely align all raster datasets to a common coordinate reference system with sub-pixel accuracy.
- Classify High-Res Data: Perform object-based image analysis (OBIA) on available high-resolution tiles to create a high-accuracy partial land cover map.
- Train Ensemble Model: Use the high-resolution classification as training data for a random forest model applied to the concurrent, wall-to-wall Sentinel-2 spectral bands and indices.
- Predict and Validate: Apply the model to the entire low-resolution dataset. Validate against held-out ground-truth data, reporting Cohen's Kappa (>0.8 acceptable).
Protocol 3: Network Augmentation and Impedance Calibration
Objective: To correct and enhance a low-detail or incomplete road network vector file for accurate transport time/cost calculation. Materials: OpenStreetMap (OSM) shapefile, GPS track logs from truck surveys, government road centerline files. Procedure:
- Topological Cleaning: Ensure network connectivity (snap vertices, remove dangles) using GIS topology tools.
- Attribute Imputation: Assign realistic average speeds based on road class from OSM. Where class is missing, infer from road width via satellite basemap measurement.
- Ground-Truthing: Collect GPS tracks from biomass trucks on key routes. Calculate actual speed profiles.
- Impedance Calibration: Adjust the speed attributes in the network file using a linear regression model:
Modeled Time = α + β * (Calculated Time from initial speeds). Calibrate α and β using GPS track data. - Gap Bridging: Digitize missing critical links visible on satellite imagery and assign conservative impedance values.
Visualizations: Workflows and Logical Relationships
Title: Mitigation Workflow for Spatial Data Pitfalls
Title: Impact Pathway from Data to Drug Development
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Toolkit for Spatial Data Quality Assurance in Biomass Research
| Tool / Reagent Category | Specific Example | Function in Mitigating Data Pitfalls |
|---|---|---|
| Geospatial Software Suites | QGIS (Open Source), ArcGIS Pro, Google Earth Engine | Platform for data auditing, gap analysis, interpolation, and network analysis. Enables protocol execution. |
| Programming Libraries | R: sf, terra, gstat. Python: geopandas, rasterio, scipy, scikit-learn |
Automates data validation, complex spatial statistics, and machine learning for data fusion. |
| Validation Datasets | High-resolution UAV orthophotos, LIDAR point clouds, RTK GPS ground truth points | Provides "gold standard" reference data for calibrating and validating enhanced low-resolution datasets. |
| Data Sources | Sentinel-2 MSI, Landsat 9, OpenStreetMap, SoilGrids, Biomass yield survey archives | Primary input data. Understanding their inherent resolution and completeness limitations is critical. |
| Cloud Compute & Storage | Google Cloud Storage, AWS S3/EC2, Microsoft Azure Blob Storage | Enables handling of large, multi-temporal raster datasets and compute-intensive processes like kriging. |
| Spatial Data Validation Tools | UN-FAO Collect Earth Online, proprietary sensor calibration kits | Facilitates systematic visual interpretation for accuracy assessment and field sensor calibration. |
This document details application notes and experimental protocols for conducting sensitivity analysis within a Geographic Information System (GIS)-integrated Linear Programming (LP) biomass supply chain optimization framework. Such research is critical for bio-based drug development, where the cost, quality, and reliable supply of biomass feedstocks (e.g., medicinal plants, algae) directly impact preclinical and clinical product development pipelines. Sensitivity analysis quantifies the robustness of the optimal supply chain design to uncertainties in key biological and economic parameters.
Key Input Parameters & Data Tables
Sensitivity analysis focuses on parameters with high uncertainty that significantly influence the LP model's objective function (typically total cost or profit).
Table 1: Key Stochastic Input Parameters for Sensitivity Analysis
| Parameter Category | Specific Example Inputs | Typical Range/Variation | Source of Uncertainty |
|---|---|---|---|
| Biomass Economics | Farm-gate price ($/dry ton) | ± 25-40% from baseline | Market volatility, policy subsidies. |
| Transportation cost ($/ton/km) | ± 20% from baseline | Fuel price fluctuations. | |
| Biological Yield | Crop yield (dry ton/hectare) | ± 30-50% from baseline | Climate, genetics, agronomic practices. |
| Biochemical Quality | Target compound concentration (%) | ± 15-25% from baseline | Plant phenotype, post-harvest handling. |
| Facility Operations | Conversion efficiency (%) | ± 10-20% from baseline | Process technology maturity. |
| Facility fixed operating cost ($) | ± 15% from baseline | Scale, labor costs. |
Table 2: Sample Baseline Data for a Hypothetical Echinacea purpurea Supply Chain
| Parameter | Value | Unit |
|---|---|---|
| Average Farm-gate Price | 550 | $/dry ton |
| Average Root Yield | 2.5 | dry ton/hectare |
| Average Alkylamide Concentration | 0.8 | % dry weight |
| Transport Cost | 0.18 | $/ton/km |
| Extraction Facility Capacity | 10,000 | dry ton/year |
| Minimum Required Annual Alkylamide | 7.5 | ton/year |
Experimental Protocols for Sensitivity Analysis
Protocol 3.1: One-Way (Univariate) Sensitivity Analysis
Objective: To isolate the effect of varying a single input parameter on the LP model's optimal solution. Materials: Baseline GIS-LP model, parameter perturbation script (Python/GAMS/AMPL), visualization software. Procedure:
- Define Baseline: Run the LP model with all parameters at baseline values. Record the optimal objective function value (e.g., Total System Cost) and key decisions (e.g., total land used, facilities opened).
- Select Parameter: Choose one input parameter (e.g., biomass price).
- Define Perturbation Range: Determine a realistic range (e.g., -40% to +40% of baseline).
- Iterate and Solve: For each incremental step (e.g., 5% intervals) within the range: a. Change the selected parameter value. b. Solve the LP model again, holding all other parameters constant. c. Record the new objective function value and solution structure.
- Analyze: Plot the objective function value against the parameter variation. Calculate the sensitivity index: (ΔObjective%/ΔParameter%). Identify "breakpoints" where the optimal supply chain network structure changes.
Protocol 3.2: Scenario-Based (Multivariate) Sensitivity Analysis
Objective: To evaluate model performance under coherent sets of assumptions representing future states. Materials: As in 3.1, plus scenario definition framework. Procedure:
- Define Scenarios: Develop 3-5 plausible scenarios (e.g., "High-Yield, High-Price," "Low-Yield, Favorable Policy").
- Bundled Parameter Adjustment: For each scenario, adjust multiple correlated input parameters simultaneously based on scenario narrative.
- Solve and Compare: Solve the LP model for each full scenario. Compare optimal networks, costs, and resource utilization across scenarios using SWOT analysis (Strengths, Weaknesses, Opportunities, Threats).
Protocol 3.3: Monte Carlo Simulation Integration
Objective: To propagate uncertainty distributions through the model to obtain a probability distribution of outcomes. Materials: As in 3.1, plus defined probability distributions for key inputs (e.g., normal for yield, triangular for price). Procedure:
- Define Distributions: Assign appropriate statistical distributions to each stochastic input parameter.
- Random Sampling: Use a random number generator to draw a set of values (a sample) from all input distributions simultaneously.
- Model Execution: Run the LP model with this sampled set of inputs.
- Iterate: Repeat steps 2-3 for a large number of iterations (N > 1000).
- Analyze Output Distribution: Analyze the resulting distribution of the objective function (e.g., mean, standard deviation, 5th-95th percentile range) to assess financial risk.
Visualizations
Sensitivity Analysis Method Selection Logic (99 chars)
Sensitivity Analysis Core Workflow (100 chars)
The Scientist's Toolkit: Essential Research Reagents & Solutions
Table 3: Key Tools for GIS-LP Sensitivity Analysis
| Tool / "Reagent" | Category | Function in Analysis |
|---|---|---|
| Linear Programming Solver (Gurobi, CPLEX) | Software | Computational engine for solving the optimization model to optimality under each parameter set. |
| Python (Pyomo, PuLP) / GAMS / AMPL | Modeling Language | Provides the framework to formulate the LP model and automate parameter changes and iteration loops. |
| Geographic Information System (ArcGIS, QGIS) | Spatial Platform | Manages, analyzes, and visualizes spatial data (biomass locations, roads, facilities) integral to the supply chain model. |
| Monte Carlo Simulation Add-in (@RISK, Python NumPy) | Statistical Library | Generates random input samples from defined probability distributions for probabilistic sensitivity analysis. |
| Sensitivity Index Calculator | Analytical Metric | Quantifies the relative influence of an input parameter on the output (e.g., Tornado Diagram generator). |
| High-Performance Computing (HPC) Cluster | Hardware | Enables the execution of thousands of LP model runs for Monte Carlo simulation in a feasible timeframe. |
Application Notes
These notes detail the integration of scenario-based stochastic programming into a GIS-Linear Programming (LP) biomass supply chain optimization model to manage risks from weather and market volatility. The core methodology enhances deterministic LP models by evaluating strategic decisions against a finite set of discrete future states (scenarios), each with an assigned probability.
1.1. Core Quantitative Parameters for Scenario Generation Key stochastic variables are derived from historical data and future projections. The following tables summarize baseline data ranges and scenario definitions.
Table 1: Key Stochastic Input Parameters & Data Sources
| Parameter | Description | Typical Data Source | Baseline Range (Example) |
|---|---|---|---|
| Biomass Yield (t/ha) | Dry matter yield per harvest cycle. | MODIS/ Landsat NDVI, soil maps, historical agronomy trials. | 8 - 22 t/ha |
| Harvest Window (days) | Number of operable days affected by precipitation & soil moisture. | NOAA CMORPH/ GPM precipitation, soil data. | 45 - 90 days |
| Feedstock Moisture (%) | Impacts logistics cost and quality. | Field sensors, weather station data. | 12% - 45% |
| Biomass Farmgate Price ($/t) | Price paid at the field edge. | USDA NASS, commodity market reports. | $60 - $95 /t |
| Diesel Fuel Price ($/gal) | Primary cost driver for transportation. | EIA weekly retail data. | $3.50 - $5.25 /gal |
Table 2: Constructed Scenarios for a Two-Dimensional Uncertainty Model
| Scenario Name | Probability | Weather Variability Assumption | Market Fluctuation Assumption |
|---|---|---|---|
| Favorable-Stable | 0.20 | +10% yield, +15% harvest days | Baseline price, -5% fuel cost |
| Adverse-Inflationary | 0.35 | -15% yield, -20% harvest days | +20% biomass price, +25% fuel cost |
| Moderate-Volatile | 0.30 | Baseline yield & harvest | ±15% biomass price, ±10% fuel cost |
| Favorable-Inflationary | 0.15 | +5% yield, +10% harvest days | +25% biomass price, +30% fuel cost |
1.2. Expected Value of Perfect Information (EVPI) Analysis EVPI quantifies the value of eliminating all uncertainty. It is calculated as the difference between the Wait-and-See (WS) solution (optimal decision per scenario) and the Here-and-Now (HN) solution (single decision before scenario realization).
Table 3: EVPI Calculation for a Sample Model Run ($ millions)
| Solution Approach | Objective Value (Net Present Value) | Calculation |
|---|---|---|
| Wait-and-See (WS) | $142.5 | ∑ (ps * NPVs) |
| Here-and-Now (HN) | $128.7 | NPV of stochastic solution |
| Expected Value of Perfect Information (EVPI) | $13.8 | WS ($142.5) - HN ($128.7) |
Experimental Protocols
Protocol 2.1: Geospatial Data Curation and Scenario Parameterization
Objective: To generate spatially-explicit input data layers for each defined scenario.
Materials: GIS software (e.g., ArcGIS Pro, QGIS), Python/R with rasterio/terra libraries, historical weather data (Daymet, PRISM), soil databases (SSURGO), land cover data (NLCD).
Procedure:
- Base Layer Preparation: Clip all spatial data (soil, land cover, road network) to the study region. Rasterize vector data to a common resolution (e.g., 30m).
- Weather Perturbation: For each scenario, apply the defined percentage change to historical daily precipitation and temperature rasters. Use agronomic growth models (e.g., APSIM) or empirical regressions to translate climate data into spatially-varying yield and harvestable day rasters.
- Economic Parameter Assignment: Assign the scenario-specific biomass price and fuel cost to corresponding logistics network arcs and biomass procurement points within the LP model's input matrices.
- Validation: Conduct cross-validation by comparing model-generated yield maps against independent county-level agricultural survey data for historical years.
Protocol 2.2: Two-Stage Stochastic Linear Programming Model Formulation & Solution
Objective: To solve the biomass supply chain design problem under uncertainty.
Materials: Optimization software (GAMS, AMPL, or Python with Pyomo), solver (CPLEX, Gurobi), high-performance computing (HPC) cluster for large-scale runs.
Procedure:
- Model Formulation:
- First-Stage Variables: Strategic, "here-and-now" decisions: Biorefinery location and capacity, depot establishment.
- Second-Stage Variables: Tactical, "wait-and-see" decisions: Biomass flow from fields to depots/refinery, inventory levels, specific harvest scheduling. These are indexed by scenario s.
- Objective Function: Minimize Total Cost = (First-Stage Capital Cost) + ∑ [ps * (Second-Stage Operational Costs)].
- Implementation: Code the model using the Sample Average Approximation (SAA) method. Generate N (e.g., 100) equally likely multi-year weather sequences via bootstrapping. Solve the resulting large-scale deterministic equivalent LP.
- Solution & Evaluation: Execute the model on HPC. Extract the first-stage decisions. Fix these decisions, then re-solve each scenario independently to evaluate the robustness of the strategic plan. Calculate performance metrics: Expected Total Cost, Value of Stochastic Solution (VSS = EEV - RP), and EVPI.
Mandatory Visualizations
Title: Stochastic GIS-LP Workflow for Biomass Supply Chain
Title: Two-Stage Stochastic Decision Tree
The Scientist's Toolkit: Research Reagent Solutions
Table 4: Essential Tools for GIS-Integrated Stochastic Biomass Supply Chain Research
| Tool / Reagent | Function / Application | Key Characteristics |
|---|---|---|
| GAMS with CPLEX/Gurobi | Algebraic modeling language and solver for formulating and solving large-scale stochastic LP models. | Handles deterministic equivalents of scenario-based models efficiently. |
| Python Stack (Pyomo, Pandas, GeoPandas) | Open-source platform for model scripting, data manipulation, and spatial analysis. | Enables integration of GIS shapefile processing with optimization model construction. |
| Google Earth Engine | Cloud-based geospatial analysis platform for processing satellite imagery and climate data. | Facilitates rapid generation of historical yield and weather anomaly layers. |
| CMIP6 Climate Projection Data | Ensemble of global climate model outputs for future scenario development. | Provides data for constructing long-term climate uncertainty scenarios (RCP/SSP). |
| SSURGO Soil Database | High-resolution soil survey geographic database for the United States. | Critical for modeling soil-specific biomass yield potential and harvestability constraints. |
| USDA NASS Quick Stats | Repository of historical agricultural production and price data. | Used for calibrating biomass yield models and establishing baseline market conditions. |
Application Notes
In the context of GIS-integrated linear programming (LP) biomass supply chain research, strategic facility location decisions represent a critical optimization frontier. While LP effectively handles continuous variables (e.g., biomass flow quantities), it is fundamentally inadequate for discrete, yes/no decisions such as whether to open a facility at a specific candidate site. Mixed-Integer Programming (MIP) extends LP by incorporating integer variables (e.g., binary variables 0 or 1), enabling simultaneous optimization of both tactical flow logistics and strategic infrastructure investment.
Core Advantages of MIP for Facility Location:
- Binary Decision Variables: Model the fixed cost of opening a facility and its associated capacity constraints.
- Economies of Scale: Capture stepwise cost functions via integer variables.
- Logical Constraints: Enforce complex business rules (e.g., "if a depot in region A is open, then a preprocessing plant in region B must also be open").
- Non-Linear Approximation: Piecewise linearize certain non-linear cost structures.
Quantitative Data Comparison: LP vs. MIP Formulations
| Aspect | Linear Programming (LP) Formulation | Mixed-Integer Programming (MIP) Formulation |
|---|---|---|
| Decision Variables | Continuous only (Flow_ij ≥ 0). | Continuous (Flowij) and Binary (Openj ∈ {0,1}). |
| Fixed Facility Cost | Cannot be modeled directly. Amortized into per-unit cost, distorting marginal economics. | Explicitly modeled: Σ (FixedCostj * Openj). |
| Facility Capacity | Soft constraint; can be violated or requires pre-defined, fixed allocation. | Hard constraint: Σi Flowij ≤ Capacityj * Openj. |
| Solution Nature | Always gives a "fractional" solution; may suggest fractional facility openings. | Provides a realistic solution with clear open/closed statuses. |
| Computational Complexity | Polynomial time (generally efficient). | NP-Hard; solution time grows exponentially with binary variables. |
| Objective Value | Often overly optimistic (lower bound), as it ignores fixed costs. | Provides a true total cost (fixed + variable), yielding a realistic optimal value. |
Typical MIP Results from a GIS-Based Biomass Study:
| Scenario | Number of Candidate Sites | Optimal # of Facilities | Total Cost (M$) | Fixed Cost (M$) | Variable Cost (M$) | CPU Solve Time (s)* |
|---|---|---|---|---|---|---|
| Base Case (MIP) | 50 | 8 | 45.2 | 15.5 | 29.7 | 1,245 |
| LP Relaxation | 50 | 12.5 (fractional) | 38.1 (infeasible) | N/A | 38.1 | 22 |
| High-Demand Case | 50 | 11 | 61.8 | 20.8 | 41.0 | 3,587 |
| CapEx-Limited Case | 50 | 6 | 52.1 | 12.0 | 40.1 | 890 |
*Using commercial solver (e.g., Gurobi, CPLEX) with a 1% optimality gap on a standard workstation.
Experimental Protocols
Protocol 1: Formulating and Solving a Capacitated Facility Location Problem (CFLP) for Biomass Depots
Objective: To determine the optimal set of depot locations and biomass flow network minimizing total system cost.
Materials: GIS data (feedstock points, candidate sites, road network), cost parameters, optimization software with MIP solver (e.g., GAMS/Pyomo with CPLEX/Gurobi, OR-Tools).
Procedure:
- Data Preprocessing (GIS Integration):
a. Using ArcGIS Pro or QGIS, calculate the transportation cost matrix (
c_ij) between each biomass sourceiand candidate depot locationjbased on road distance and biomass bulk density. b. Aggregate feedstock supply quantities (s_i) from point data to county or district centroids. c. Define fixed capital cost (f_j) and maximum throughput capacity (cap_j) for each candidate depotj.
Model Formulation (MIP): a. Sets: Define sets
I(source regions) andJ(candidate depots). b. Variables: *x_ij ≥ 0: Continuous, tons of biomass shipped fromitoj. *y_j ∈ {0,1}: Binary, 1 if depotjis opened, 0 otherwise. c. Objective Function: MinimizeΣ_j f_j * y_j + Σ_i Σ_j c_ij * x_ij. d. Constraints: * Supply:Σ_j x_ij ≤ s_ifor alli. (Ship no more than available supply). * Demand/Capacity:Σ_i x_ij ≤ cap_j * y_jfor allj. (Flow to a depot is zero if not opened, and capped if opened). * Non-negativity and Integrality: As defined.Solver Configuration & Execution: a. Input model and data into the modeling environment. b. Set solver parameters: MIP optimality gap tolerance (e.g., 0.01%), time limit (e.g., 10,000s). c. Execute the solver and monitor convergence.
Solution Analysis & Validation: a. Extract optimal
y_jvalues (open facilities) andx_ijflows. b. Map the results in GIS to visualize the selected supply chain network. c. Perform sensitivity analysis on key parameters (e.g.,f_j,cap_j).
Protocol 2: Heuristic Warm-Start for Large-Scale MIP Problems
Objective: To reduce computational time for large-scale MIP by providing a high-quality initial feasible solution.
Procedure:
- Solve LP Relaxation: Solve the MIP model with binary constraints relaxed (
0 ≤ y_j ≤ 1). Record solutiony*_j. - Heuristic Rounding: Apply a greedy-add heuristic:
a. Sort candidate facilities
jin descending order of their relaxed flowΣ_i x_ij/f_j(efficiency ratio). b. Initialize an empty set of open facilities. c. Iteratively add the facility with the highest efficiency ratio that improves the objective, re-optimizing flows after each addition, until no improvement. - Fix and Solve: Fix the binary variables
y_jfrom the heuristic solution as a starting point for the full MIP solver. Provide this "warm start" to the solver, which then uses branch-and-bound/cut to prove optimality.
Mandatory Visualizations
Diagram 1: MIP vs LP Optimization Workflow
Diagram 2: Logical Constraints in MIP Facility Location
The Scientist's Toolkit: Research Reagent Solutions
| Item | Function in GIS-MIP Research |
|---|---|
| GIS Software (ArcGIS Pro, QGIS) | Spatial data processing, network analysis, cost matrix generation, and result visualization. |
| Optimization Modeling Language (GAMS, Pyomo, AMPL) | Provides a high-level, algebraic environment to formulate the MIP model separately from data. |
| Commercial MIP Solvers (Gurobi, CPLEX, FICO Xpress) | High-performance solvers implementing advanced algorithms (branch-and-bound, cutting planes, heuristics) to find optimal solutions. |
| Open-Source Solvers (SCIP, CBC) | Accessible solvers for prototyping and validating models without commercial license barriers. |
| Python/R with Libraries (pandas, geopandas, ortools) | Enables scripting of end-to-end workflows from GIS processing to model construction and result analysis. |
| High-Performance Computing (HPC) Cluster Access | Essential for solving large-scale, real-world instances where solve times can extend to days. |
| Sensitivity & Scenario Analysis Scripts | Automated scripts to test model robustness against parameter uncertainty (e.g., biomass yield, fuel price). |
Model Calibration and Iterative Refinement Based on Field Data
Application Notes
Within the broader thesis of GIS-integrated linear programming (LP) for biomass supply chain optimization, model calibration using field data is critical for transforming theoretical frameworks into reliable decision-support tools. LP models, while structurally robust, rely on accurate input parameters—such as biomass yield, moisture content, transportation cost coefficients, and equipment throughput—to generate viable solutions. These parameters are inherently variable across spatial and temporal scales. This document outlines protocols for the systematic collection of field data and its iterative use in refining LP model coefficients, ensuring outputs align with real-world operational constraints and biological variability. The focus is on creating a closed-loop system where model predictions inform data collection priorities, and new data continuously enhances model fidelity.
Quantitative Data from Calibration Studies
Table 1: Common Field-Measured Parameters for Biomass LP Model Calibration
| Parameter | Typical Range (Example Feedstock: Miscanthus) | Measurement Method | Impact on LP Model Coefficient |
|---|---|---|---|
| Dry Matter Yield | 10-25 Mg/ha/year | Destructive sampling, weigh wagons | Objective function (revenue), supply constraint RHS |
| Harvestable Moisture Content | 15-55% (wet basis) | Near-infrared spectroscopy (NIR), oven drying | Transportation cost (weight), preprocessing energy cost |
| Harvest Throughput | 0.5-1.5 ha/hour | GIS telematics, timed plots | Equipment capacity constraint coefficient |
| Transportation Time (Field to Depot) | 20-60 minutes | GPS logging, route analysis | Transportation cost matrix coefficient |
| Biomass Density (Baled) | 140-220 kg/m³ | Dimension and mass measurement | Transportation & storage volume constraints |
Table 2: Iterative Calibration Results from a Notional Study
| Calibration Cycle | Mean Absolute Error (MAE): Predicted vs. Actual Supply Cost ($/Mg) | Key Parameter Adjusted | Field Data Source for Adjustment |
|---|---|---|---|
| Initial Model (Cycle 0) | 38.50 | N/A | Literature values |
| Cycle 1 | 22.10 | Transportation cost per km-ton | GPS logs from 15 truck routes |
| Cycle 2 | 12.40 | Field-to-road access time (h) | Interviews + GIS terrain analysis |
| Cycle 3 | 8.75 | Seasonal yield decay factor | Multi-harvest time-point sampling |
Experimental Protocols
Protocol 1: Geotagged Biomass Yield Sampling for Spatial LP Calibration Objective: To generate high-resolution yield data for calibrating spatial supply constraints in the GIS-LP model. Materials: GPS-enabled tablet, sampling quadrat (1m x 1m), drying oven, scale, GIS software (e.g., QGIS, ArcGIS Pro). Procedure:
- Stratified Random Sampling: Overlay a grid on the target field in GIS. Randomly select 3-5 sampling points within each soil type or management zone polygon.
- Field Data Collection: Navigate to each point using GPS. Place the quadrat, harvest all biomass within it, and record fresh weight.
- Subsample Processing: Take a ~500g subsample, seal in a pre-weighed bag, and record its fresh weight.
- Dry Matter Determination: Dry the subsample at 105°C to constant weight (≈48 hours). Record dry weight.
- Data Integration: Calculate dry matter yield per hectare for each point. Create a point shapefile with attributes:
Point_ID,X_Coord,Y_Coord,Fresh_Wt_kg,Dry_Matter_%,Yield_Mg_per_ha. - Spatial Interpolation: Use Kriging or Inverse Distance Weighting (IDW) in GIS to create a continuous yield surface raster. This raster informs the
supply_quantityparameter at each candidate sourcing location in the LP model.
Protocol 2: Transportation Logistics Timing Study Objective: To calibrate the cost and time coefficients for the LP transportation network arcs. Materials: Fleet telematics units (or smartphone with logging app), biomass trucks, processed data (origin-destination matrix, road network layer). Procedure:
- Route Definition: Define representative origin-destination (O-D) pairs (e.g., Field01 to Biorefinery, StorageDepot_Alpha to Biorefinery).
- Data Logging: Equip trucks operating on these O-D pairs with logging devices. Record timestamped GPS location, speed, and idle status for a minimum of 10 trips per major O-D pair under varied conditions.
- Data Processing: Clean logs to extract
travel_time,loading_time,unloading_time, andwait_time. Map routes to the GIS road network. - Coefficient Calculation: Calculate average total cycle time and effective travel speed for each road class (e.g., highway, county road, unimproved road). Regress time against distance for each class to derive
time_per_kmcoefficients. - Model Update: Update the LP model's transportation constraint matrix (A) and objective function cost coefficients (c) for the corresponding arcs using the derived
time_per_kmand associated fuel/labor costs.
Protocol 3: Iterative Model Refinement Loop Objective: To systematically reduce discrepancy between model-predicted and observed system performance. Materials: Calibrated baseline LP model, new field validation dataset, optimization software (e.g., GAMS, Python's PuLP), statistical analysis software. Procedure:
- Baseline Simulation: Run the LP model with current parameters. Export key outputs: predicted supply tonnage from each zone, selected depot locations, total cost.
- Validation Data Collection: Collect a new, independent set of field operational data (e.g., actual tons delivered from zones, actual costs incurred) over a subsequent season or operational period.
- Discrepancy Analysis: Calculate performance metrics (MAE, MAPE) comparing predicted vs. actual values for key outputs (see Table 2). Perform sensitivity analysis on the model to identify the 2-3 parameters to which total cost is most sensitive.
- Targeted Re-measurement: Design and execute a focused field study (using Protocol 1 or 2) to re-measure the high-sensitivity parameters identified in Step 3.
- Parameter Update & Re-optimization: Update the LP model with the new parameter set. Re-run the optimization.
- Convergence Check: Compare new metrics with previous cycle. Continue iteration until MAE/MAPE falls below a pre-defined acceptable threshold (e.g., <10%) or improvements between cycles become negligible (<2%).
Visualizations
Iterative Calibration Workflow for GIS-LP Models
GIS-LP Integration with Calibration Feedback Loop
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials for Field Data-Driven Calibration
| Item | Function in Calibration Research |
|---|---|
| GPS Data Logger / Telematics Unit | Precisely records geospatial location and time for route analysis, yield point mapping, and spatial data tagging. Fundamental for linking field observations to GIS layers. |
| Portable Near-Infrared (NIR) Spectrometer | Provides rapid, in-field estimation of biomass composition parameters (e.g., moisture, lignin, cellulose) for real-time quality calibration, reducing reliance on lab assays. |
| GIS Software with Spatial Analyst | Platform for creating, managing, analyzing, and visualizing spatial data. Used for interpolation (kriging), network analysis, and raster calculation to generate model inputs. |
| Linear Programming Solver (e.g., GAMS, CPLEX, PuLP) | Computational engine that performs the optimization calculations. Must be capable of handling large-scale, spatially explicit models integrated via scripting with GIS. |
| Scripting Environment (Python/R) | Used to automate data pipelines from field logs → GIS processing → LP matrix generation → results analysis, ensuring reproducible and scalable calibration workflows. |
| Precision Scale & Drying Oven | Gold-standard equipment for establishing dry biomass weight, the key metric for yield calculation and for validating/calibrating indirect measurement tools (e.g., NIR). |
Measuring Success: Validating Your Optimized Supply Chain Against Traditional Methods
This application note details protocols for validating a multi-objective Linear Programming (LP) model within a Geographic Information System (GIS)-integrated biomass-to-bioactive compound supply chain. The broader thesis context posits that optimizing for cost alone leads to suboptimal environmental outcomes. Rigorous validation of cost, operational efficiency, and carbon footprint metrics is therefore critical for informing sustainable practices in biomass sourcing for drug development.
Core Validation Metrics & Quantitative Data
The following three metric categories are calculated from the GIS-LP model outputs and validated against real-world or simulated benchmark data.
Table 1: Summary of Core Validation Metrics
| Metric Category | Specific Metric | Unit | Calculation Basis | Ideal Benchmark |
|---|---|---|---|---|
| Economic (Cost) | Total Delivered Cost | $/dry ton | Harvest + Pre-processing + Transportation + Storage | ≤ Market Price of Conventional Feedstock |
| Cost per Unit Bioactive Yield | $/mg | Total Cost / Total Recovered Compound | Minimization Target | |
| Operational Efficiency | Biomass Utilization Rate | % | (Mass to Biorefinery / Total Harvestable Mass) * 100 | > 85% |
| Supply Chain Resilience Index | Unitless | (Number of Viable Pathways / Total Pathways) | Maximization Target | |
| Environmental (Carbon) | Total Carbon Footprint | kg CO₂-eq/dry ton | LCA of all supply chain operations (see Protocol 3.2) | Minimization Target |
| Carbon per Unit Bioactive Yield | kg CO₂-eq/mg | Total Footprint / Total Recovered Compound | Comparative to Petrochemical Route |
Table 2: Example Quantitative Comparison of Two Model Scenarios
| Validation Metric | Scenario A: Cost-Optimized | Scenario B: Multi-Objective Optimized | Validation Method |
|---|---|---|---|
| Total Delivered Cost ($/dry ton) | 58.70 | 62.40 | Historical Contract Data |
| Cost per Unit Yield ($/mg) | 0.42 | 0.45 | Pilot-Scale Extraction Data |
| Biomass Utilization Rate (%) | 92.3 | 88.1 | Satellite/Yield Map Analysis |
| Resilience Index | 0.65 | 0.82 | Monte Carlo Simulation |
| Total Carbon Footprint (kg CO₂-eq/dry ton) | 124.5 | 89.2 | GHG Protocol Calculation |
| Carbon per Unit Yield (kg CO₂-eq/mg) | 0.89 | 0.64 | Comparative LCA Database |
Detailed Experimental Protocols for Validation
Protocol 3.1: Validating Cost and Efficiency Metrics via Simulated Field Trials
Objective: To empirically verify model-predicted costs and efficiency using a controlled, small-scale supply chain simulation.
Materials & Workflow:
- Define Test Polygon: Select a representative 50-acre parcel within the GIS study area.
- Implement Model Prescription: Execute harvest, collection, and pre-processing operations as scheduled by the LP model.
- Data Logging: Record actual time, fuel consumption, labor hours, biomass moisture loss, and equipment yields at each node.
- Calculation & Comparison: Convert logged data into actual cost ($/dry ton) and utilization rate (%) for the test parcel. Compare to model-predicted values for the same geographic unit. Calculate Mean Absolute Percentage Error (MAPE).
Protocol 3.2: Validating Carbon Footprint via Tier-2 Life Cycle Assessment (LCA)
Objective: To ground-truth the model's embedded carbon accounting with standardized LCA methodology.
Methodology:
- Goal & Scope: Define functional unit as 1 dry ton of processed biomass delivered to the biorefinery gate. Include cradle-to-gate boundaries.
- Life Cycle Inventory (LCI):
- Primary Data Collection: Use fuel logs from Protocol 3.1. Measure direct N₂O/CH₄ emissions from soil using static chambers in test plots (if applicable).
- Secondary Data Sourcing: Use emission factors from the latest EPA GHG Inventory or Ecoinvent v3.9+ database for upstream inputs (fertilizer, herbicide production), machinery manufacture, and electricity grid composition.
- Impact Assessment: Calculate global warming potential (GWP) using IPCC AR6 (2021) 100-year characterization factors. Sum contributions from diesel combustion, soil emissions, upstream inputs, and transportation.
- Validation: Compare the calculated GWP per dry ton from this protocol against the carbon footprint metric output by the GIS-LP model for the same system boundary.
Visualization of Validation Framework
Diagram Title: Validation Workflow for GIS-LP Biomass Model
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials & Tools for Validation
| Item / Solution | Function in Validation | Example / Specification |
|---|---|---|
| GIS Software (e.g., ArcGIS Pro, QGIS) | Spatial analysis of biomass yield, route planning, and visual comparison of model outputs vs. reality. | Must support raster calculator and network analysis tools. |
| Linear Programming Solver (e.g., Gurobi, CPLEX) | The computational engine for solving the multi-objective optimization model. | Academic licenses available; benchmark for solution speed and accuracy. |
| Life Cycle Inventory Database | Provides secondary emission factors for comprehensive carbon footprint validation. | Ecoinvent, USDA LCA Digital Commons, or EPA USEEIO. |
| Fuel Flow Meter | Attaches to equipment to collect primary fuel consumption data during field validation. | Must be compatible with diesel engines and have data logging capability. |
| Soil Emission Chambers | Measure direct field-level GHG emissions (N₂O, CH₄) for carbon LCA validation. | Static opaque chambers with syringe ports for gas sampling. |
| Moisture Analyzer | Determines dry weight of biomass samples at various supply chain nodes to calculate utilization rate. | Halogen-based moisture balance providing rapid results. |
| Statistical Software (e.g., R, Python SciPy) | Performs comparative statistical analysis (MAPE, t-test) between model predictions and validation data. | Custom scripts for automated metric calculation and visualization. |
Benchmarking Against Heuristic or Experience-Based Sourcing Strategies
Application Notes and Protocols
1. Introduction and Context Within a GIS-integrated linear programming (LP) biomass supply chain research framework, optimizing feedstock sourcing is critical. Advanced LP models determine theoretically optimal solutions based on cost, distance, biomass quality, and logistical constraints. However, in practice, procurement often relies on heuristic rules or experience-based strategies (e.g., "source from the three nearest suppliers," "always use Supplier X for high-quality feedstock"). Benchmarking the LP model's performance against these real-world heuristics quantifies the value of optimization and identifies gaps for practical implementation. This protocol details the methodology for systematic benchmarking.
2. Data Compilation and Structuring The following quantitative data must be compiled from historical records, GIS analysis, and LP model outputs.
Table 1: Data Sources and Key Metrics for Benchmarking
| Data Category | Source | Key Metrics | Format |
|---|---|---|---|
| Heuristic Strategy Data | Historical procurement records, interviews with sourcing managers. | Total cost ($/ton), average haul distance (km), quality variability (%), supplier count, reliability (% on-time delivery). | Time-series, aggregated annual/seasonal. |
| GIS Data | Geodatabases, remote sensing. | Supplier locations (point geometry), road network (line geometry), biomass yield (polygon attributes), travel time/cost matrices. | Vector layers (Shapefile, GeoJSON). |
| LP Model Output | Optimization solver (e.g., Gurobi, CPLEX) results. | Optimal total cost ($), optimal sourcing allocation (tons per supplier), optimal route selection, shadow prices of constraints. | Tabular data, spatial allocation maps. |
| Market & Biophysical Data | Government databases, lab analysis. | Biomass purchase price ($/ton), moisture content (%), carbohydrate content (%), ash content (%). | Tabular data. |
Table 2: Benchmarking Performance Indicators (KPI Table)
| Performance Indicator | Heuristic Strategy Value | LP Optimized Value | Delta (LP - Heuristic) | % Improvement |
|---|---|---|---|---|
| Total Sourcing Cost ($) | [Insert Value] | [Insert Value] | [Insert Value] | [Insert Value] |
| Average Transport Distance (km) | [Insert Value] | [Insert Value] | [Insert Value] | [Insert Value] |
| Quality Consistency (Std. Dev. of Key Attribute) | [Insert Value] | [Insert Value] | [Insert Value] | [Insert Value] |
| Model vs. Reality Gap | N/A | Shadow price of binding constraints | N/A | Identifies costliest real-world limits. |
3. Experimental Protocols
Protocol 1: Heuristic Strategy Reconstruction and Simulation Objective: To formally model and quantify the performance of experience-based sourcing. Materials: Historical transaction database, GIS software (e.g., ArcGIS Pro, QGIS), spreadsheet or statistical software. Procedure:
- Conduct structured interviews with sourcing agents to codify heuristic rules (e.g., "preference ranking," "distance thresholds").
- Apply these rules programmatically to historical demand scenarios using GIS network analysis to calculate simulated transport distances and costs.
- Aggregate simulated purchase costs and transport costs to compute total simulated cost of the heuristic strategy.
- Output: A spatial map of sourcing regions and a table of costs (Table 2) for the heuristic approach.
Protocol 2: GIS-LP Integrated Model Formulation and Execution Objective: To generate the theoretically optimal benchmark. Materials: GIS software, linear programming solver, Python/R with optimization libraries (e.g., PuLP, ompr). Procedure:
- Data Preprocessing: Use GIS to create a cost matrix from all candidate sourcing locations (e.g., biomass collection points) to the biorefinery, incorporating road network tariffs and distance.
- Model Formulation:
- Decision Variable: Xij = Tons of biomass shipped from source i to facility j.
- Objective Function: Minimize Total Cost = Σ (Purchase Costi + Transport Costij) * Xij.
- Constraints: Supply capacity at i, demand at j, biomass quality blending constraints (e.g., max ash content), non-negativity.
- Model Execution: Solve the LP using a MILP solver. Extract optimal allocations and total cost.
- Spatial Mapping: Map the optimal sourcing pattern from the LP solution using GIS.
- Output: Optimal cost (Table 2), spatial allocation map, and constraint analysis.
Protocol 3: Scenario-Based Robustness Benchmarking Objective: To test both strategies under variable conditions (e.g., demand surge, supplier failure). Materials: Outputs from Protocol 1 & 2, scenario definition parameters. Procedure:
- Define perturbation scenarios: ±20% demand change, removal of top 2 heuristic-preferred suppliers.
- Re-run the heuristic simulation (Protocol 1) under each scenario.
- Re-optimize the LP model (Protocol 2) under each scenario's new constraints.
- Compare the cost increase and strategic flexibility (e.g., sourcing diversification) of each method.
- Output: A comparison table of cost deviations across scenarios.
4. Visualizations
Title: Biomass Sourcing Benchmarking Workflow
Title: GIS-LP Model Constraint Structure
5. The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Tools for GIS-LP Biomass Supply Chain Research
| Tool / Reagent | Function in Experiment | Example Product/Software |
|---|---|---|
| Geographic Information System (GIS) | Spatial data management, network analysis, cost surface generation, and visualization of sourcing patterns. | ArcGIS Pro, QGIS, GRASS GIS. |
| Linear/MILP Solver | Computational engine to solve the optimization model and find the globally optimal solution. | Gurobi, IBM CPLEX, COIN-OR CBC. |
| Programming Interface | Glue layer to integrate GIS, data, and the solver; used for model formulation and automation. | Python (PuLP, GeoPandas), R (ompr, sf), MATLAB. |
| Spatial Database | Storage and efficient querying of large, multi-attribute geospatial datasets (yield, land use, roads). | PostGIS (PostgreSQL), SpatiaLite. |
| Biomass Property Analyzer | Determines key biochemical attributes (carbohydrates, lignin, ash) for quality constraint formulation. | NIR Spectrometer, HPLC, ASTM-standard lab assays. |
| Network Analysis Toolkit | Calculates accurate travel times, distances, and least-cost paths for transport logistics. | Esri Network Analyst, OSMnx, pgRouting. |
This application note details a comparative analysis of two biomass feedstock sourcing models for a biorefinery producing pharmaceutical-grade precursors. The study is situated within a broader thesis on Geographic Information Systems (GIS) integrated Linear Programming (LP) for optimizing biomass supply chains. The objective is to quantify the advantages of a GIS-LP optimized network over a conventional regional sourcing strategy in terms of cost, logistical efficiency, and environmental impact.
Experimental Protocols
Protocol A: Design of GIS-LP Optimized Network
Objective: To formulate and solve a spatially-explicit LP model minimizing total system cost for biomass procurement. Methodology:
- Data Acquisition: Gather geospatial data (shapefiles) for candidate feedstock supply zones (50km radius), road networks, and biorefinery location.
- Attribute Assignment: For each supply zone, calculate and assign:
- Available biomass yield (tonnes/km²).
- Procurement cost ($/tonne).
- Distance to biorefinery via road network (km).
- Model Formulation (LP):
- Decision Variable: Tonnage sourced from each supply zone i.
- Objective Function: Minimize [Σ(Procurement Costi * Tonnagei) + Σ(Transport Cost/km * Distancei * Tonnagei)].
- Constraints:
- Total biomass procured ≥ Biorefinery demand (e.g., 50,000 tonnes/year).
- Tonnage from any zone ≤ Zone's sustainable availability.
- Non-negativity.
- Solution: Execute optimization using an LP solver (e.g., CPLEX, GLPK) integrated within the GIS platform (e.g., ArcGIS Pro with Python API).
Protocol B: Simulation of Conventional Regional Sourcing
Objective: To model a standard industry practice of sourcing biomass from the nearest available regions until demand is met. Methodology:
- Buffer Creation: Create a concentric buffer around the biorefinery location.
- Sequential Allocation: Allocate biomass from the closest supply zone first until its sustainable limit is reached.
- Demand Fulfillment: Expand the buffer radius incrementally, incorporating zones in order of increasing distance, until the total annual demand is satisfied.
- Cost Calculation: Compute total cost using the same per-unit procurement and transport cost metrics as Protocol A.
Protocol C: Sustainability Impact Assessment
Objective: To evaluate and compare the carbon footprint of both sourcing networks. Methodology:
- Activity Data: Use the tonnage and transport distance outputs from Protocols A and B.
- Emission Factor: Apply a standardized emissions factor (e.g., 0.09 kg CO₂-eq/tonne-km for heavy-duty truck transport).
- Calculation: Compute total operational greenhouse gas (GHG) emissions for each scenario: Σ(Tonnagei * Distancei * Emission Factor).
Data Presentation & Results
Table 1: Quantitative Comparison of Sourcing Strategies
| Metric | GIS-LP Optimized Network | Conventional Regional Sourcing | Relative Improvement |
|---|---|---|---|
| Total Annual Cost | $4,825,000 | $5,450,000 | -11.5% |
| Average Sourcing Distance | 82 km | 115 km | -28.7% |
| Number of Supply Zones Utilized | 8 | 12 | -33.3% |
| Total Transport GHG Emissions | 369,000 kg CO₂-eq | 517,500 kg CO₂-eq | -28.7% |
| Model Computational Time | ~45 minutes | ~5 minutes | +800% |
Table 2: Key Research Reagent Solutions & Materials
| Item | Function in the Study |
|---|---|
| GIS Software (e.g., ArcGIS Pro, QGIS) | Platform for spatial data management, analysis, and visualization of supply zones and networks. |
| Linear Programming Solver (e.g., PuLP, GLPK, CPLEX) | Computational engine to solve the optimization model and determine the cost-minimal feedstock allocation. |
| Spatial Analyst Extension | GIS toolkit for performing raster calculations (e.g., biomass yield per zone) and proximity analysis. |
| Network Analyst Extension | GIS toolkit for calculating accurate road network distances between supply zones and the biorefinery. |
| Python/R API | Scripting interface to integrate GIS operations with the LP model formulation and solution process. |
| Biomass Yield & Land Use Datasets | Foundational geospatial data (e.g., from USDA, ESA) used to quantify available feedstock. |
Visualizations
Title: GIS-LP Optimization Methodology Workflow
Title: Cost Breakdown: GIS-LP vs. Conventional
Title: Spatial Configuration of the Two Sourcing Networks
1. Introduction Within the broader thesis on GIS-integrated linear programming (LP) for biomass supply chain optimization, this protocol details the critical limitations stemming from computational and data requirements. These constraints are pivotal for researchers and scientists in bioenergy and drug development who rely on such models for sourcing bioactive plant materials. Understanding these boundaries is essential for realistic project scoping and robust model interpretation.
2. Application Notes on Key Limitations
2.1 Computational Complexity in Large-Scale LP-GIS Models Integrating high-resolution GIS data (e.g., land cover, slope, road networks) with a biomass LP model exponentially increases problem size. The computational expense is governed by the number of variables (biomass sources, processing facilities, routes) and constraints (capacity, sustainability, economic).
Table 1: Computational Demand Scaling with Model Resolution
| Spatial Resolution (Cell Size) | Approximate Number of Source Cells | LP Variables (Typical) | Estimated Solve Time (Gurobi/Cplex) | RAM Requirement |
|---|---|---|---|---|
| 1 km² | 10,000 | ~500,000 | 45-90 minutes | 8-16 GB |
| 100 m² | 1,000,000 | ~50,000,000 | 10+ hours (may not converge) | 64+ GB |
| 30 m² (Landsat) | ~11,000,000 | Exceeds standard solver limits | Intractable for direct solve | >256 GB |
Application Note: Researchers must use spatial aggregation or clustering techniques (see Protocol 3.1) to reduce problem size, accepting a loss of spatial detail for computational feasibility.
2.2 Data Acquisition, Quality, and Pre-processing Burden The model's accuracy is contingent on diverse, current, and clean geospatial and tabular data. Key data layers include biomass yield, harvest costs, transportation networks, and facility locations. Inconsistencies in format, projection, or accuracy can invalidate results.
Table 2: Critical Data Requirements and Associated Challenges
| Data Layer | Typical Source | Key Challenge | Impact on Model |
|---|---|---|---|
| Biomass Yield | Remote Sensing (NDVI), USDA Surveys | Temporal variability, calibration to dry mass | Directly affects supply quantity and cost. |
| Transportation Network | OSM, TIGER | Road weight restrictions, seasonal access | Alters optimal routing and cost. |
| Land Parcel Ownership | County Plat Maps | Privacy restrictions, fragmented data | Constrains source availability and contracts. |
| Real-time Traffic/Weather | APIs (e.g., NOAA, Google) | Dynamic, streaming data | Requires stochastic LP, increasing complexity. |
3. Experimental Protocols for Mitigation
Protocol 3.1: Spatial Aggregation for Model Tractableity Objective: To reduce the number of spatial supply units in the LP model while preserving geographic and economic fidelity.
- Data Input: Raster layer of biomass yield (Mg/ha); Shapefile of road network.
- Clustering Algorithm: Apply the k-means or hierarchical clustering algorithm in a GIS (e.g., ArcGIS Pro
Grouping Analysistool or Pythonscikit-learn) using feature vectors of [Xcoordinate, Ycoordinate, Yield, Traveltimeto_depot]. - Cluster Validation: Determine optimal cluster number (k) using the Elbow Method on within-cluster sum of squares (WCSS). Target reducing source locations by 70-90%.
- Attribute Aggregation: For each cluster, calculate total biomass (sum of yields) and centroid location. Use centroid as the new source node.
- Model Integration: Feed aggregated source nodes into the LP framework. The transportation cost from a cluster centroid to a facility is calculated using the road network. Validation: Compare total system cost and biomass flow from the aggregated model versus a high-resolution sample. Accept <5% deviation in total cost.
Protocol 3.2: Data Gap Imputation and Uncertainty Analysis Objective: To address missing or poor-quality yield data and quantify its impact on the optimal supply chain.
- Gap Identification: Overlay yield data with land cover. Flag pixels with null or outlier values (e.g., yield >95th percentile).
- Imputation Method: For missing agricultural residue data, use a Multiple Imputation by Chained Equations (MICE) approach. Predictors can include: soil productivity index, historical crop yield, and precipitation (30-year normals).
- Stochastic LP Formulation: Create 10 distinct scenarios of biomass availability using imputed data ranges. Formulate a two-stage stochastic LP model where first-stage decisions are facility locations, and second-stage decisions are biomass flows under each scenario.
- Solve & Analyze: Solve using a solver with stochastic programming capabilities (e.g., IBM CPLEX). Output the Expected Value of Perfect Information (EVPI) to quantify the economic value of obtaining perfect data.
4. Mandatory Visualizations
Diagram 1: Mitigation Workflow for Limitations
Diagram 2: Impact of Data and Compute Limits
5. The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Software and Data Tools for GIS-LP Research
| Item Name | Function/Benefit | Example Vendor/Source |
|---|---|---|
| Commercial LP/MIP Solver | High-performance algorithms for solving large optimization models. Essential for convergence. | Gurobi, IBM ILOG CPLEX, FICO Xpress |
| Geospatial Clustering Library | Implements algorithms to aggregate spatial data points, reducing model size. | Python: scikit-learn, GeoPandas; R: sf, cluster |
| Stochastic Programming Extension | Allows formulation and solution of optimization-under-uncertainty models. | Integrated in Gurobi/CPLEX, PySP (Pyomo) |
| Cloud Computing Platform | Provides on-demand high RAM/CPU resources for intractable local problems. | Google Cloud Platform, Amazon AWS, Microsoft Azure |
| Curated Biomass Database | Provides pre-processed, peer-reviewed yield and cost data, reducing acquisition time. | USDA Bioenergy Knowledge Discovery Framework, NREL BioFuels Atlas |
| Geospatial Data API | Streams real-time or historical contextual data (weather, traffic) into models. | Google Maps Platform, OpenWeatherMap API |
Introduction Within the framework of GIS-integrated linear programming (LP) biomass supply chain research, optimization transcends theoretical logistics. This Application Note demonstrates how precise, algorithm-driven sourcing of plant-derived compounds directly accelerates pre-clinical drug discovery by standardizing input material, reducing variability, and enabling high-throughput screening (HTS) of natural product libraries. We detail protocols and data showing the direct correlation between optimized supply and experimental efficiency.
Quantitative Impact of Optimized Biomass Sourcing on Pre-Clinical Workflow Table 1: Comparative Metrics for Standard vs. Optimized Biomass in Lead Compound Identification
| Metric | Standard Sourcing (Historical Average) | GIS-LP Optimized Sourcing | % Improvement |
|---|---|---|---|
| Biomass Collection Time | 14.2 ± 3.1 days | 5.5 ± 1.2 days | 61.3% |
| Active Compound Concentration Variability (RSD) | 22.5% | 8.7% | 61.3% |
| Crude Extract Screening Hits (per 10k samples) | 12 | 19 | 58.3% |
| Time to Isolate 10mg of Pure Lead Compound | 42 days | 28 days | 33.3% |
| Failed Experiments due to Insufficient/Inconsistent Material | 18% | 5% | 72.2% |
Application Notes & Protocols
Protocol 1: GIS-LP Guided Biomass Procurement for Withania somnifera (Ashwagandha) Objective: To collect root biomass with maximized and consistent withanolide content using spatial optimization. Methodology:
- Model Inputs: Integrate soil pH GIS layers, historical precipitation data, and known cultivation sites into an LP model minimizing travel distance while maximizing predicted withanolide yield.
- Field Collection: Deploy teams to coordinates generated by the LP solution. Collect root samples (n=50 plants per zone) using standardized SOPs (wash, slice, immediate flash-freeze in liquid N₂).
- Validation: Perform immediate HPLC-UV analysis on a random subset (n=5 per batch) to quantify withanolide A and withaferin A. Accept batch if RSD <10% for target compounds.
Protocol 2: High-Throughput Screening (HTS) of Optimized Natural Product Libraries Objective: To screen a library of optimized plant extracts for NF-κB pathway inhibition. Experimental Workflow:
- Library Preparation: Prepare 384-well plates with standardized crude extracts (10 µg/µL in DMSO) sourced from optimized biomass.
- Cell Assay: Seed HEK-293 cells stably transfected with an NF-κB response element driving luciferase (NF-κB-RE-luc) at 10,000 cells/well.
- Stimulation & Readout: Pre-treat with extract (1µg/mL final) for 1 hr, then stimulate with TNF-α (10 ng/mL). After 6 hrs, lyse cells and measure luciferase activity.
- Data Analysis: Normalize to TNF-α-only control (100% activation) and DMSO vehicle (0% inhibition). Z'-factor >0.5 indicates robust assay.
Visualization: Experimental and Logical Relationships
Title: From GIS Data to Accelerated Pre-Clinical Research
Title: NF-κB Pathway & Assay Inhibition Point
The Scientist's Toolkit: Research Reagent Solutions Table 2: Essential Materials for HTS of Natural Product Libraries
| Item | Function & Rationale |
|---|---|
| Cryogenically Milled Plant Biomass | Homogeneous, chemically stable starting material from optimized sourcing; ensures reproducibility. |
| Automated Solid-Phase Extraction (SPE) System | Enables high-throughput, consistent fractionation of crude extracts with minimal compound degradation. |
| NF-κB-RE-luc Reporter Cell Line | Genetically engineered cell line providing a sensitive, quantitative readout of pathway activity. |
| 384-Well Assay-Ready Plates (Prefilled with Extracts) | Library plates prepared from standardized extracts minimize plate-to-plate variability in screening. |
| Luminometer with Injector | Allows rapid, sequential measurement of luciferase activity post-lysis for kinetic or endpoint assays. |
| GIS & LP Software Suite (e.g., ArcGIS, Gurobi) | For creating the spatial optimization models that define the harvest parameters for biomass collection. |
Conclusion
The integration of GIS and Linear Programming presents a transformative, data-driven methodology for designing robust biomass supply chains in drug discovery. This approach moves beyond intuition-based sourcing, enabling researchers to systematically minimize costs, ensure reliable biomass quality and quantity, and embed sustainability principles from the outset. The foundational knowledge establishes the 'why,' the methodological framework provides the actionable 'how,' while troubleshooting and validation ensure practical, reliable outcomes. For biomedical research, adopting this optimized paradigm means more predictable timelines for natural product extraction, reduced R&D overhead, and a stronger foundation for translating ecological resources into clinical candidates. Future directions involve integrating real-time IoT sensor data from fields, applying machine learning for yield prediction, and expanding models to encompass full lifecycle analysis, ultimately creating agile supply networks that can accelerate the journey from natural resource to novel medicine.