OpenLCA for Bioenergy Systems: A Comprehensive Guide for Life Cycle Assessment (LCA) in Biotech and Pharmaceutical Research
This article provides a detailed guide for researchers, scientists, and drug development professionals on applying OpenLCA software to model and analyze the environmental impacts of bioenergy systems.
OpenLCA for Bioenergy Systems: A Comprehensive Guide for Life Cycle Assessment (LCA) in Biotech and Pharmaceutical Research
Abstract
This article provides a detailed guide for researchers, scientists, and drug development professionals on applying OpenLCA software to model and analyze the environmental impacts of bioenergy systems. It covers foundational concepts, methodological workflows, practical troubleshooting, and validation techniques. By bridging the gap between life cycle assessment theory and practical application, this guide empowers professionals to conduct robust LCAs of bio-based feedstocks, waste-to-energy processes, and sustainable biomanufacturing strategies, supporting informed decision-making in green chemistry and sustainable drug development.
Bioenergy LCA Essentials: Core Concepts and OpenLCA Fundamentals for Researchers
This application note provides a structured framework for modeling and analyzing bioenergy systems using OpenLCA software. For researchers and development professionals, the systematic deconstruction of these systems into discrete, assessable unit processes is critical for conducting life cycle assessment (LCA), calculating carbon intensity, and evaluating sustainability trade-offs in bio-based product development. This protocol aligns with a broader thesis on enhancing the granularity and accuracy of bioenergy models in LCA databases.
Core Bioenergy System Components & Quantitative Data
A bioenergy system is defined by interconnected stages. The quantitative data below, essential for OpenLCA inventory creation, is summarized from current literature and industry reports.
Table 1: Key Feedstock Characteristics & Conversion Yields
| Feedstock Type | Avg. Dry Yield (ton/ha/yr) | Avg. Energy Content (GJ/ton) | Typical Conversion Pathway | Fuel Yield (GJ/ton feedstock) |
|---|---|---|---|---|
| Corn Stover | 4.5 | 17.5 | Biochemical (Ethanol) | 8.1 |
| Switchgrass | 12.0 | 19.0 | Thermochemical (Pyrolysis) | 12.5 |
| Microalgae (Lipid-rich) | 25.0 (volumetric) | 21.0 | Transesterification (Biodiesel) | 13.2 |
| Forest Residues | 3.0 (sustainable harvest) | 18.5 | Direct Combustion | 16.8 |
| Waste Cooking Oil | N/A | 37.0 | Esterification (Biodiesel) | 34.1 |
Table 2: Life Cycle GHG Emission Ranges for Biofuel Pathways (g CO₂-eq/MJ fuel)
| Fuel Product | Feedstock Cultivation & Transport | Conversion Process | Total (Low-High) | Key Source of Variation |
|---|---|---|---|---|
| Corn Ethanol | 15-25 | 25-35 | 45-75 | Land Use Change, Co-product Credit |
| Cellulosic Ethanol | 5-15 | 10-20 | 20-45 | Feedstock Logistics, Enzyme Use |
| Algal Biodiesel | 20-40 (System Energy) | 30-50 | 60-110* | Algae Growth PBR Energy, Drying |
| Biomass FT-Diesel | 5-15 | 15-25 | 25-50 | Gasification Efficiency, H₂ Source |
*Indicates high uncertainty and technology readiness variability.
Experimental Protocols for Critical System Parameters
Protocol 2.1: Determining Feedstock Biochemical Composition for Yield Modeling
Objective: To quantitatively analyze the compositional profile of lignocellulosic biomass for accurate yield prediction in biochemical conversion models within OpenLCA.
Materials:
- Dried, milled feedstock sample (<1 mm particle size)
- ANKOM200 Fiber Analyzer or equivalent
- HPLC system with refractive index detector
- Standard solutions (glucose, xylose, arabinose, lignin)
Method:
- Extractives Removal: Soxhlet extract 5g sample with ethanol for 6 hours. Dry residue.
- Structural Carbohydrates & Lignin: a. Digest 0.3g extracted sample with 3mL 72% H₂SO₄ at 30°C for 1 hour with agitation. b. Dilute to 4% H₂SO₄ concentration and autoclave at 121°C for 1 hour. c. Filter through crucible. Retain filtrate for sugar analysis and solid for lignin.
- Acid-Insoluble Lignin (AIL): Dry crucible with residue at 105°C to constant weight. Ash at 575°C for 4 hours. AIL = (residue weight - ash weight) / sample weight.
- Sugar Monomers: Analyze filtrate by HPLC to quantify glucose, xylose, arabinose. Apply correction factors for hydrolysis degradation.
- Calculation: Report composition as % dry weight of extractives-free biomass. Use sugar yields to calculate theoretical ethanol yield via stoichiometric conversion (e.g., 0.51 g ethanol/g glucose).
Protocol 2.2: Measuring Methane Potential via Anaerobic Digestion (BMP Assay)
Objective: To generate primary data on biogas yield from organic waste feedstocks for inclusion in OpenLCA waste-to-energy inventories.
Materials:
- Automatic Methane Potential Test System (AMPTS II) or batch reactors
- Inoculum (adapted anaerobic sludge)
- Substrate (characterized organic waste)
- Gas-tight serum bottles, water displacement apparatus
- Biogas composition analyzer (GC-TCD)
Method:
- Setup: In 500mL bottles, combine inoculum (300mL, 2-3 g VS/L) and substrate at an inoculum-to-substrate ratio of 2:1 on a volatile solids (VS) basis. Include blanks (inoculum only) and positive controls (microcrystalline cellulose).
- Conditioning: Flush headspace with N₂/CO₂ mix (70:30) for 2 min. Seal with butyl rubber stoppers.
- Incubation: Place in shaking incubator at 37°C ± 1°C for 30 days.
- Measurement: Manually or automatically record daily biogas production via water displacement. Periodically sample headspace gas for CH₄/CO₂ analysis via GC.
- Calculation: Subtract blank gas production. Report cumulative methane yield as NL CH₄/g VS substrate added at standard temperature and pressure.
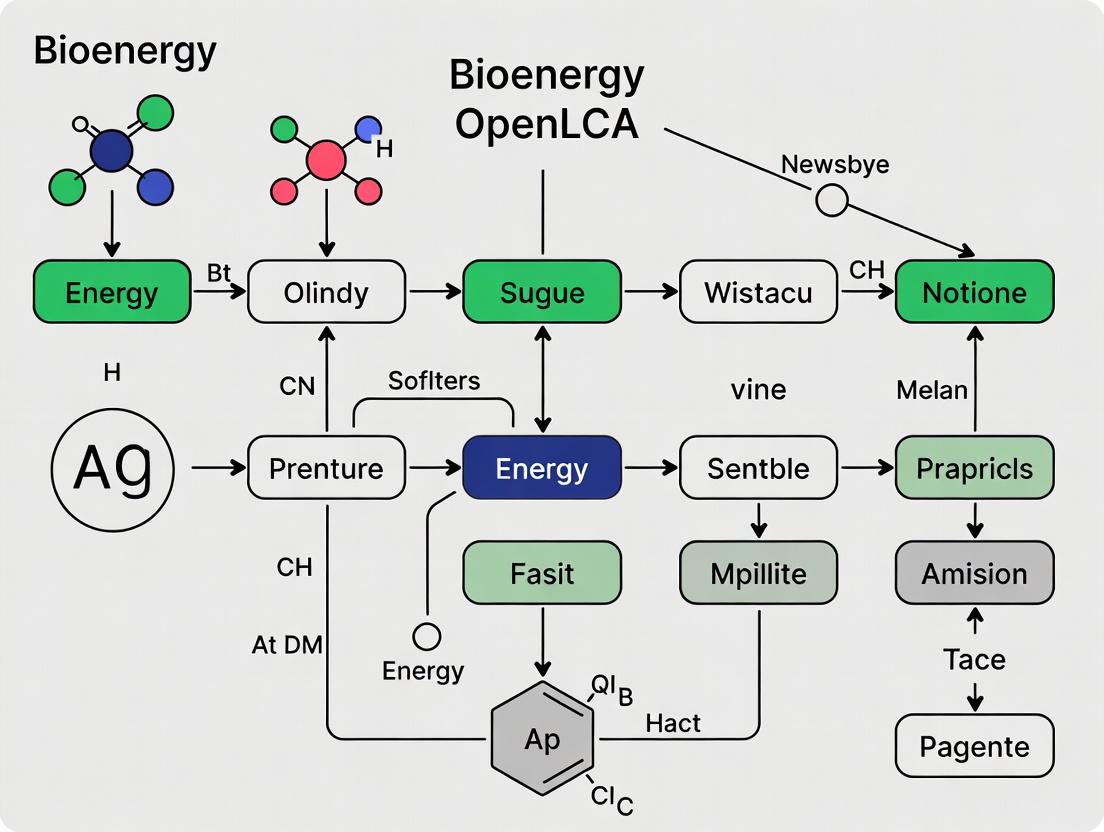
System Visualization & Workflow Diagrams
Title: Bioenergy System Stages and Flows
Title: OpenLCA Bioenergy Assessment Workflow
The Scientist's Toolkit: Research Reagent & Solution Essentials
Table 3: Key Research Reagents & Materials for Bioenergy Analysis
| Item/Category | Example Product/Specification | Primary Function in Bioenergy Research |
|---|---|---|
| Enzymatic Hydrolysis Cocktail | CTec3, HTec3 (Novozymes) | Synergistic cellulase/hemicellulase blends for saccharification of pretreated biomass to fermentable sugars. |
| Anaerobic Digestion Inoculum | Adapted anaerobic granular sludge (e.g., from wastewater plant) | Provides consortium of microbes (hydrolytic, acidogenic, acetogenic, methanogenic) for BMP assays. |
| Lipid Extraction Solvent | Chloroform-Methanol (2:1 v/v), Bligh & Dyer method | Efficiently extracts total lipids from microalgal biomass for biodiesel potential quantification. |
| Internal Standard for GC Analytics | n-Heptane (for biogas), Methyl heptadecanoate (for FAME) | Quantitative calibration and correction for analyte loss in gas chromatography analysis of biofuels. |
| Lignin Reference Standard | Kraft Lignin (Sigma-Aldrich, 471003) | Used for calibration curves in quantitative lignin analysis (e.g., Klason method). |
| Trace Element Solution | Modified Balch's vitamins and minerals solution | Provides essential micronutrients (Ni, Co, Mo, Se) to maintain robust microbial consortia in fermentation or digestion. |
| Solid Catalyst for Thermocatalysis | HZSM-5 Zeolite (Si/Al=40) | Acidic catalyst for catalytic fast pyrolysis or upgrading, promoting deoxygenation and aromatization. |
| DNA/RNA Shield for Metagenomics | Zymo Research DNA/RNA Shield | Preserves nucleic acids from microbial communities in conversion processes for omics-based pathway analysis. |
Why LCA is Critical for Evaluating Bioenergy Sustainability in Biotech
Application Notes: OpenLCA in Bioenergy Systems Research
Life Cycle Assessment (LCA) is the definitive methodology for quantifying the environmental impacts of biotech-derived bioenergy, from feedstock cultivation to end-use. Within biotech, where processes like engineered microbial fermentation or enzymatic hydrolysis are pivotal, LCA moves sustainability claims from qualitative to quantitative. OpenLCA, as an open-source platform, is critical for enabling transparent, customizable, and reproducible assessments tailored to novel biotechnological pathways.
Key Application Areas:
- Feedstock Comparison: Assessing genetically modified energy crops versus agricultural waste streams.
- Process Optimization: Pinpointing environmental hotspots in biorefinery setups (e.g., high enzyme loading, steam demand).
- Technology Readiness Level (TRL) Scaling: Modeling impacts from lab-scale experiments to pilot and commercial scale.
- Policy & Certification Support: Generating data for compliance with schemes like the EU Renewable Energy Directive (RED II).
Summary of Recent Comparative LCA Data (Hypothetical Scenarios Modeled in OpenLCA): Table 1: Comparative Global Warming Potential (GWP) for Different Bioethanol Pathways
| Feedstock & Conversion Technology | GWP (kg CO₂-eq/GJ ethanol) | Key Contributing Process (from OpenLCA hotspot analysis) |
|---|---|---|
| Corn Stover (Conventional Enzymatic) | 18.5 | Enzyme production, biogas management from wastewater. |
| Corn Stover (Engineered Hyper-producer Yeast) | 15.2 | Reduced enzyme load, but higher energy for sterile fermentation. |
| Genetically Modified Switchgrass (Consolidated Bioprocessing) | 8.7 | Lower fertilizer input (crop mod.), combined hydrolysis/fermentation step. |
| Fossil Gasoline (Baseline) | 94.2 | Crude extraction, refining, and combustion. |
Table 2: Impact Assessment for Algal Biodiesel (Open Pond System)
| Impact Category | Result (per 1000 MJ biodiesel) | Normalized to Reference System (Fossil Diesel) |
|---|---|---|
| Global Warming Potential | 45 kg CO₂-eq | -52% |
| Eutrophication Potential | 12.3 kg PO₄-eq | +185% |
| Water Consumption | 4500 L | +310% |
| Land Use | 0.05 m²a crop eq | -98% |
Protocol: Conducting an Attributional LCA for a Novel Microbial Biofuel Process Using OpenLCA
Objective: To model the cradle-to-gate environmental impacts of biofuel produced via a genetically modified E. coli strain fermenting lignocellulosic sugars.
I. Goal and Scope Definition
- Functional Unit: 1 Megajoule (MJ) of purified biofuel (e.g., isobutanol) at the biorefinery gate.
- System Boundary: Includes: (1) Feedstock production & pretreatment, (2) Enzyme & nutrient production, (3) Inoculum preparation, (4) Sterile fermentation in bioreactor, (5) Downstream purification. Excludes fuel distribution and use.
- Impact Categories: Mandatory: Global Warming Potential (GWP), Acidification, Eutrophication. Recommended: Resource Depletion (fossil), Water Use.
II. Life Cycle Inventory (LCI) Data Collection Protocol
- Lab-Scale Primary Data:
- Fermentation Yield: Run triplicate fermentations in a 5L bioreactor. Measure substrate depletion (HPLC) and product titer (GC-MS) hourly. Calculate average yield (g product / g substrate).
- Utilities: Log total electricity (kWh) consumed by bioreactor (agitator, pumps, control system, sterilization). Monitor direct steam consumption for sterilization (kg).
- Material Inputs: Precisely record masses of all inputs: engineered strain media components (tryptone, yeast extract), antibiotics, induction agent (IPTG), nutrients, antifoam, and purification solvents.
- Background Data: Source upstream processes (electricity grid mix, enzyme production, chemical synthesis) from commercial LCA databases (e.g., ecoinvent, Agribalyse) imported into OpenLCA.
III. OpenLCA Modeling Workflow
- Create Project & Flows: Open new project. Define all elementary (CO₂, NOx) and product flows (isobutanol, waste biomass) in the Flow Database.
- Model Unit Processes: For each step (see diagram), create a process and link input/output flows.
- Example - Fermentation Process: Input Flows: Pretreated substrate (kg), Process water (L), Engineered E. coli inoculum (kg), Electricity (kWh), Sterile air (m³). Output Flows: Isobutanol (kg), CO₂ (from respiration, kg), Spent fermentation broth (kg).
- Parameterize & Scale: Create parameters (e.g.,
yield_ferm) from experimental data. Use them in process formulas to scale from lab (5L) to conceptual pilot scale (10,000L). - Check for Missing Exchanges: Run the Validation to ensure all flows are connected to a source or endpoint.
IV. Impact Assessment & Interpretation
- Calculate: Select LCIA method (e.g., ReCiPe 2016 Midpoint (H)). Run calculation.
- Analyze Contributions: Use Contribution Analysis to identify top 3 contributing processes to GWP.
- Perform Sensitivity: Vary key parameters (e.g., electricity source, yield) by ±20% to determine most sensitive assumptions.
V. Reporting Document all data sources, allocation procedures (if any), and assumptions in alignment with ISO 14044 standards.
Visualizations
Diagram 1: OpenLCA Modeling Workflow for Microbial Biofuel
Diagram 2: System Boundary for Biotech Biofuel LCA
The Scientist's Toolkit: Key Research Reagent Solutions for LCA-Informed Bioprocess Development
Table 3: Essential Materials for Generating Primary LCA Inventory Data
| Reagent / Material | Function in Bioprocess Development | Relevance to LCA Data Quality |
|---|---|---|
| Defined Minimal Media Kits | Provides precise, reproducible nutrient composition for fermentation, eliminating variability from complex extracts. | Allows accurate allocation of resource use to the product; improves scaling accuracy. |
| Genetically Engineered Strain (e.g., E. coli KO/OV with biofuel pathway) | Core production organism. Performance (titer, rate, yield) is the single greatest determinant of process efficiency. | Directly defines the mass and energy balances modeled in OpenLCA. |
| Activity-Calibrated Enzyme Cocktails (e.g., cellulase/hemicellulase mixes) | For lignocellulosic feedstock saccharification. Activity dictates required loading (mg/g biomass). | Enzyme production is often a major environmental hotspot. Accurate loading data is critical. |
| High-Precision Metabolite Standards (for GC-MS/HPLC) | Quantification of substrates (sugars), products (biofuels), and by-products (organic acids, glycerol). | Establishes the carbon yield and system stoichiometry, fundamental for LCI. |
| Sterilization Indicators (Autoclave tape, biological spore strips) | Validates the sterility protocol, a significant energy consumer in bioreactor operation. | Provides data for modeling the energy burden of sterilization on the system. |
This primer details the application of the open-source Life Cycle Assessment (LCA) software, OpenLCA, within bioenergy systems research. It provides specific protocols for modeling bioenergy pathways, enabling researchers to quantify environmental impacts consistently. The content supports a broader thesis on the standardization of LCA methodologies for sustainable bioenergy and biochemical development.
Core OpenLCA Workflow for Bioenergy Systems
A standardized workflow is essential for reproducible LCA in bioenergy research. The following diagram illustrates the primary procedural steps.
Diagram Title: OpenLCA Standard LCA Workflow
Key Research Reagent Solutions (OpenLCA & LCA Context)
Essential digital "reagents" for conducting LCA research on bioenergy systems in OpenLCA are listed below.
| Item Name | Function in Research |
|---|---|
| OpenLCA Software | Core platform for modeling product systems, calculating inventories, and impact assessment. |
| Ecoinvent Database | Comprehensive, commercial background database providing validated inventory data for energy, materials, and processes. |
| AGRIBALYSE Database | Provides specific LCI data for agricultural and bioenergy feedstocks (e.g., corn, sugarcane, forestry). |
| EF 3.0 (EU) Method | LCIA method providing a standardized set of impact categories (e.g., climate change, eutrophication) for the European context. |
| ReCiPe 2016 Method | A harmonized global LCIA method offering midpoint (problem-oriented) and endpoint (damage-oriented) indicators. |
| OpenLCA Nexus | Integrated repository for finding, comparing, and downloading LCA databases and LCIA methods directly within OpenLCA. |
| GreenDelta olca-ipc | Python library for programmatically linking OpenLCA with computational environments for advanced analysis and parameterization. |
Protocol: Modeling a Generic Biomass-to-Bioelectricity System
Goal & Scope Definition Protocol
- Objective: Quantify the global warming potential (GWP) of 1 kWh of electricity generated from cultivated woody biomass.
- System Boundaries: Cradle-to-gate with energy substitution. Includes feedstock cultivation, harvesting, transport, conversion, and emissions. Excludes power grid infrastructure.
- Functional Unit: 1 kilowatt-hour (kWh) of low-voltage electricity delivered to the grid.
- Allocation: Apply economic allocation between co-products (e.g., electricity, heat) based on market prices.
Life Cycle Inventory (LCI) Modeling Protocol
- Create a New Project in OpenLCA: Name it "BioenergySystemsResearch".
- Import Required Databases: Use OpenLCA Nexus to install and activate the Ecoinvent 3.8 (or latest) cut-off database and the EF 3.0 LCIA method.
- Model the Product System:
- Create a new Process named "Bioelectricity from Managed Forest".
- In the Inputs/Outputs tab, link elementary flows from the database to build the supply chain.
- Key process links to establish:
Biomass cultivation -> Biomass transport -> Combined heat & power plant -> Electricity to grid. - Use the Parameter feature to set variables (e.g., transport distance, boiler efficiency) for scenario analysis.
Impact Assessment & Interpretation Protocol
- Calculation: In the Calculations panel, select the modeled product system and the EF 3.0 method. Run the calculation.
- Results Analysis: Navigate to the Results section. The Total Impacts table provides the GWP (in kg CO2-eq) per functional unit.
- Contribution Analysis: Use the Analysis -> Contribution Analysis tool to drill down into which process or flow contributes most to the total GWP.
- Sensitivity Check: Use the Parameter feature to vary key inputs (e.g., biomass yield, transport distance) by ±20% and recalculate to assess result robustness.
Data Presentation: Comparative LCIA Results for Bioenergy Pathways
The table below summarizes hypothetical impact assessment results for different bioenergy pathways, calculated using the EF 3.0 method. Data is illustrative for protocol demonstration.
Table 1: Comparative Life Cycle Impact Assessment for 1 kWh of Bioelectricity (Illustrative Data)
| Impact Category | Unit | Woody Biomass CHP | Agricultural Residue Gasification | Biogas from Anaerobic Digestion |
|---|---|---|---|---|
| Climate change | kg CO2-eq | 0.120 | 0.065 | 0.210 |
| Freshwater eutrophication | kg P-eq | 1.5E-05 | 8.0E-06 | 4.3E-05 |
| Acidification | mol H+ eq | 0.0021 | 0.0015 | 0.0038 |
| Land use | Pt | 0.85 | 0.10 | 1.25 |
CHP: Combined Heat and Power. Pt: Percentage of species loss per area-time unit (EF 3.0 specific).
Advanced Analysis: Uncertainty and Scenario Workflow
For robust conclusions, researchers must evaluate uncertainty and compare scenarios. The following workflow details this process.
Diagram Title: Uncertainty & Scenario Analysis Flow
Protocol: Monte Carlo Uncertainty Analysis
- Define Parameter Uncertainty: For key model parameters (e.g.,
fertilizer_amount), open the parameter dialog. Set a Distribution type (e.g.,Normal) and define the standard deviation based on literature data. - Configure Calculation: In the Calculation dialog, switch the Type from
FasttoMonte Carlo Simulation. Set the number of runs (e.g., 1000). - Execute and Analyze: Run the calculation. Open the Results and navigate to the Statistics tab to view mean, median, and confidence intervals (e.g., 2.5% and 97.5% percentiles) for each impact category.
Application Notes on Core Terminologies in OpenLCA for Bioenergy Systems
Life Cycle Assessment (LCA) is a foundational methodology for evaluating the environmental impacts of bioenergy systems, from feedstock cultivation to energy conversion. Within the OpenLCA software environment, precise definition of three core terminologies is critical for robust, reproducible research relevant to pharmaceutical and scientific industries seeking sustainable energy solutions.
Functional Unit (FU): The quantified performance of a product system for use as a reference unit. In bioenergy research, the FU enables equitable comparison between disparate systems (e.g., biodiesel vs. bioethanol). For instance, comparing processes based on "1 MJ of net energy delivered" or "1 kg of produced bio-based chemical precursor" standardizes assessments.
System Boundary: Defines which unit processes are included in the LCA model. A cradle-to-gate boundary for a lignocellulosic ethanol process may include: feedstock cultivation, harvest, transport, pretreatment, enzymatic hydrolysis, fermentation, and product separation. A cradle-to-grave boundary would add distribution, use, and end-of-life. Strategic boundary selection is paramount when assessing biogenic carbon flows and by-product allocation in integrated biorefineries.
Impact Categories: Represent environmental issues of concern to which the LCA results may be assigned. Selection is guided by the goal and scope. For bioenergy systems, beyond global warming potential (GWP), critical categories include eutrophication (from fertilizer runoff), acidification (from emissions), land use (change), and water consumption. OpenLCA’s impact assessment methods (e.g., ReCiPe, EF 3.0) provide characterization factors to translate inventory data (kg of emission) into impact category results (e.g., kg CO₂-eq for GWP).
Table 1: Common Functional Units and System Boundaries in Bioenergy LCA Studies
| Study Focus | Typical Functional Unit (FU) | Typical System Boundary | Primary Impact Categories Assessed |
|---|---|---|---|
| Transportation Biofuel | 1 MJ of lower heating value (LHV) fuel | Cradle-to-grave (Well-to-Wheels) | Global Warming, Acidification, Eutrophication |
| Bioenergy for Pharmaceutical Process Heat | 1 GJ of steam produced | Cradle-to-gate (up to plant exit) | Global Warming, Particulate Matter, Resource Depletion |
| Biobased Chemical (e.g., Succinic Acid) | 1 kg of purified product, 99.9% purity | Cradle-to-gate | Global Warming, Land Use, Fossil Resource Scarcity |
Experimental Protocols for LCA Modeling in OpenLCA
Protocol 1: Defining a Comparative FU for Bioethanol and Syngas Pathways
- Objective: To establish a common basis for comparing environmental performance of enzymatic bioethanol and thermochemical syngas production from the same biomass feedstock.
- Materials: OpenLCA software, life cycle inventory (LCI) databases (e.g., ecoinvent, Agribalyse), process flow data for both pathways.
- Methodology:
- Determine the primary function of both systems: To deliver energy for industrial chemical synthesis.
- Calculate the net energy output (in MJ) of each pathway, accounting for all internal energy uses.
- Set the FU as "1 GJ of net bio-energy content available for downstream chemical production."
- In OpenLCA, model each pathway separately. Scale all input and output flows of each model so that the 'net energy output' flow equals 1 GJ.
- Document all energy conversion efficiencies and allocation procedures used in the calculation.
Protocol 2: Implementing a System Boundary for Algal Biodiesel with Nutrient Recycling
- Objective: To model a system boundary that includes recycled nutrient flows, a key feature in advanced bioenergy systems.
- Materials: OpenLCA software, primary data on algae growth, lipid extraction, transesterification, and anaerobic digestion of residues.
- Methodology:
- Draw the system diagram: Map all unit processes from algae cultivation to biodiesel combustion.
- Define inclusion principle: Include all processes materially contributing to the FU (1 MJ biodiesel) and for which data is available. Exclude human labor, capital equipment (unless significant).
- Model recycling: Create a product flow "Recycled N-P Nutrients" from the anaerobic digestion process. Connect this as an input to the algae cultivation process, displacing a proportion of virgin fertilizer input.
- Set cut-off: Apply a 1% mass/energy cut-off rule relative to the total inputs/outputs of the FU.
- In OpenLCA, use the product system builder to link all unit processes within the defined boundary. Ensure recycled flows are correctly identified to avoid cut-off errors.
Protocol 3: Calculating Impact Category Results Using the EF 3.0 Method
- Objective: To perform a life cycle impact assessment (LCIA) on a biomass gasification process.
- Materials: Completed LCI model in OpenLCA, EF 3.0 (Environmental Footprint) LCIA method package installed.
- Methodology:
- Selection: In the LCIA Methods pane, select the "EF 3.0" method set. It contains numerous categories (e.g., Climate change, Freshwater eutrophication).
- Calculation: Right-click on the product system and select Calculate. Choose the selected EF 3.0 method.
- Analysis: Navigate to the Results section. The software displays the contribution of each elementary flow (emissions, resource uses) to each impact category, expressed in category-specific units (e.g., kg CO₂-eq for climate change).
- Normalization & Weighting (Optional): Apply the normalization and weighting sets within EF 3.0 to generate single scores, clearly stating their use is for comparative internal analysis only.
Visualization of LCA Structure and Workflow
Title: OpenLCA Bioenergy Study Workflow
Title: Cradle-to-Gate System Boundary for Biogas
The Scientist's Toolkit: Essential Research Reagents & Solutions for LCA
Table 2: Key "Research Reagent Solutions" for Conducting LCA in OpenLCA
| Item/Category | Function in the LCA "Experiment" | Example/Note |
|---|---|---|
| LCI Databases | Provide background inventory data for upstream/downstream processes (e.g., electricity grid, chemical production). | ecoinvent, Agribalyse, USLCI. Essential for modeling supply chains. |
| LCIA Method Packages | Contain the characterization factors that translate inventory data into impact category indicators. | ReCiPe 2016, EF 3.0, IPCC 2021 GWP. Choice influences results. |
| Allocation Procedures | Methodological "reagents" to partition environmental burdens between co-products (e.g., ethanol and DDGS). | Allocation by mass, energy, economic value, or system expansion. |
| Parameter & Uncertainty Data | Allow for stochastic modeling and sensitivity analysis, testing the robustness of conclusions. | Mean values and distributions (e.g., lognormal) for key inputs like crop yield. |
| OpenLCA Plugins | Extend software functionality for specific analytical needs. | The GeoJSON plugin for regionalized assessment, the JSON-LD import/export. |
| Primary Process Data | Primary "reagent" for foreground system modeling. Must be collected from experiments, pilots, or industry. | Material/energy balances, emission factors, and yields from your specific bioenergy process. |
Life Cycle Assessment (LCA) databases provide the foundational inventory data required for modeling environmental impacts. Within the context of bioenergy systems research using OpenLCA, selecting the appropriate database is critical for result accuracy and relevance. The following table summarizes the key quantitative and qualitative characteristics of three prominent databases.
Table 1: Core Database Comparison for Bioenergy LCA
| Feature | Ecoinvent | Agri-Footprint | USLCI |
|---|---|---|---|
| Primary Scope | Global, multi-sector | Global, agriculture & food | United States, multi-sector |
| Spatial Granularity | Global, continental, country-specific | Country & region-specific (e.g., US Corn Belt, EU-27) | U.S. national & regional |
| Temporal Reference | Recent year (e.g., 2019 for v3.9) | Recent year (e.g., 2015-2020 for v6.0) | Periodic updates (baseline often ~2012-2020) |
| Data Type | Mostly unit process (allocated & system) | Unit process (with extensive allocation options) | Unit process and aggregate |
| Key Bioenergy Relevance | Background systems, energy mixes, chemicals | Biomass feedstocks, crop production, land use | U.S.-specific energy, transport, and material flows |
| License Model | Commercial license required | Commercial license required | Open Access (Public Domain) |
| Update Frequency | Major versions every 2-3 years | Major versions periodically | Irregular, project-dependent |
| Integration with OpenLCA | Directly supported via native (.zolca) or ILCD formats | Supported via EcoSpold1, ILCD, or OpenLCA native formats | Supported via ILCD format |
Application Notes for Bioenergy Systems in OpenLCA
Note 1: Database Selection Protocol The choice of database must align with the goal of the bioenergy study. For comprehensive assessments, a hybrid approach is recommended:
- Use Agri-Footprint to model the foreground system: cultivation, harvesting, and pre-processing of biomass feedstocks (e.g., corn stover, miscanthus).
- Use Ecoinvent to model background processes: machinery, electricity grid mixes, fertilizer production, and transportation.
- Use USLCI to regionalize the study for a U.S. context, particularly for substituting U.S.-specific grid electricity, fuel mixes, or material processes.
Note 2: Critical Data Quality Assessment Before modeling, conduct a data quality check using the pedigree matrix approach (based on ISO 14044). For each critical flow (e.g., nitrogen fertilizer, diesel), assess:
- Technological representativeness: Does the dataset match the technology of the bioenergy system?
- Geographical representativeness: Is the data from a comparable region?
- Temporal representativeness: Is the data less than 10 years old?
- Completeness: Are all relevant inputs and outputs included?
Note 3: Handling Multifunctionality & Allocation Bioenergy systems often involve co-products (e.g., distiller's grains from corn ethanol). Protocol:
- In Agri-Footprint, apply the allocation method (mass, energy, economic) that reflects the underlying physical relationships or the chosen system boundary.
- In Ecoinvent, prefer the use of "system process" datasets which apply allocation at the database level, or use the "allocation at the point of substitution" (APOS) system model cuts.
- Document the chosen method and justify its selection in line with the goal of the study.
Experimental Protocol: Conducting a Comparative LCA of Biofuel Feedstocks
Objective: To compare the cradle-to-gate environmental impacts of producing 1 MJ of energy content from switchgrass and corn grain for bioethanol production within a U.S. Midwest context using OpenLCA.
Materials & Software:
- OpenLCA software (v2.x or later)
- Agri-Footprint database (licensed)
- Ecoinvent database (licensed, preferably U.S.-adapted data where available)
- USLCI database (downloaded)
- Impact assessment method (e.g., TRACI 2.1, ReCiPe 2016)
Procedure:
Step 1: Goal & Scope Definition. 1.1. Define the functional unit: "1 MJ of lower heating value (LHV) of bioethanol ready for leaving the biorefinery gate." 1.2. Define system boundaries: Include feedstock cultivation (inputs, field operations), harvest, transport to biorefinery, and conversion to ethanol. Exclude distribution, vehicle use, and end-of-life. 1.3. Define allocation procedure: Economic allocation between ethanol and co-products (e.g., DDGS) at the biorefinery stage.
Step 2: Inventory Modeling in OpenLCA. 2.1. Create a new project. 2.2. Import and link databases: Import Agri-Footprint, Ecoinvent, and USLCI into the OpenLCA workspace. Use the "Database merge" function cautiously, preferring to keep databases separate and linking processes via product flows. 2.3. Model the foreground system: * Create a new process for "Switchgrass Ethanol (US Midwest)." * Add input flows: "Switchgrass, at farm (US)" from Agri-Footprint. * Add input flows for conversion: "Electricity, medium voltage (US)" from USLCI, "Heat, natural gas (US)" from Ecoinvent/USLCI, "Enzymes" from Ecoinvent. * Add output flows: "Ethanol" (1 MJ LHV) and "Dried Distillers Grains with Solubles (DDGS)". * Open the "Parameters" tab, define the mass of DDGS produced per MJ ethanol based on literature. Apply economic allocation factors (e.g., 80% to ethanol, 20% to DDGS) using the "Allocation" tab. 2.4. Link to background databases: Ensure the switchgrass feedstock process from Agri-Footprint correctly links to its sub-processes (fertilizer, diesel, etc.). Manually check and redirect any default links to more regionally appropriate datasets from USLCI or Ecoinvent if necessary (e.g., U.S. diesel instead of Swiss diesel). 2.5. Repeat Step 2.3-2.4 for "Corn Grain Ethanol (US Midwest)," using "Corn, grain, at farm (US)" from Agri-Footprint as the primary feedstock.
Step 3: Impact Assessment & Interpretation. 3.1. Calculate the LCIA: Select both ethanol processes, choose the TRACI 2.1 impact method, and run the calculation. 3.2. Analyze results: Export results to a table. Identify key contributors (e.g., fertilizer production, on-field N2O emissions, biorefinery natural gas use) for each impact category (e.g., Global Warming Potential, Eutrophication). 3.3. Perform contribution analysis: Use OpenLCA's analysis features to drill into individual processes and flows contributing to the total impact. 3.4. Conduct sensitivity analysis: Test the influence of key parameters (e.g., allocation factors, crop yield, transport distance) by creating scenario variants in OpenLCA.
Workflow for Biofuel Feedstock LCA in OpenLCA
The Scientist's Toolkit: Essential Research Reagent Solutions for Bioenergy LCA
Table 2: Essential Digital & Data "Reagents" for Bioenergy LCA Research
| Item (Tool/Database) | Primary Function in Bioenergy LCA Research |
|---|---|
| OpenLCA Software | The core "reactor" for modeling, linking processes, calculating impacts, and analyzing results. |
| Agri-Footprint DB | Provides high-resolution, agricultural-specific inventory data for biomass cultivation and processing. |
| Ecoinvent DB | Supplies robust, peer-reviewed background data for energy, materials, and industrial processes. |
| USLCI DB | Offers critical, regionally representative U.S. data for grounding studies in a specific national context. |
| Elementary Flow DBs | (e.g., CO2, N2O, NOx, PO4---) The "chemical standards" for quantifying emissions and resource use. |
| Impact Method (TRACI/ReCiPe) | The "assay kit" that translates inventory flows into environmental impact category scores. |
| Pedigree Matrix | A quality assurance tool to score data reliability across technological, geographical, and temporal criteria. |
| Allocation Procedure | A methodological rule-set for partitioning environmental burdens between co-products (e.g., ethanol, DDGS). |
Database Integration Logic in OpenLCA
Step-by-Step OpenLCA Workflow: Building and Analyzing Bioenergy Models
Application Notes
A robust project setup is foundational for Life Cycle Assessment (LCA) of bioenergy systems. This protocol, framed within a thesis on OpenLCA application, provides a structured approach for researchers to define the critical initial parameters of an LCA study, ensuring scientific rigor, reproducibility, and relevance to stakeholders in bioenergy and related fields.
Primary Goals: The overarching goals of an LCA for bioenergy typically include: 1) Quantifying the environmental footprint (e.g., GHG emissions, eutrophication potential) of a bioenergy pathway; 2) Comparing its performance against fossil fuel counterparts or other renewable alternatives; 3) Identifying environmental hotspots within the supply chain for targeted optimization; and 4) Informing policy development or corporate sustainability strategies.
Defining the System Scope: A comprehensive scope definition must specify:
- System Boundaries: The selection of a "cradle-to-grave," "cradle-to-gate," or "well-to-wheel" boundary determines which life cycle stages are included. For bioenergy, this often encompasses feedstock cultivation, harvesting, transportation, conversion (e.g., fermentation, gasification), energy distribution, and end-use.
- Technological Scope: Detailed description of the conversion technology (e.g., anaerobic digestion, pyrolysis), feedstock type (e.g., corn stover, Miscanthus), and co-product handling methods (e.g., allocation, system expansion).
- Geographical & Temporal Scope: The region of feedstock production and energy generation, along with the reference year for data, are critical due to spatial and temporal variations in agronomy, grid electricity, and technology performance.
Functional Unit (FU): The FU is the quantified performance of the product system that serves as the reference basis for all calculations. It must be relevant, measurable, and additive. For bioenergy systems, common FUs include:
- 1 MJ of delivered heat, electricity, or biofuel (e.g., ethanol).
- 1 km traveled by a specific vehicle class.
- 1 hectare of land managed for a year (when assessing land-use impacts).
Data Requirements: High-quality, spatially and temporally representative data is imperative. Primary data should be collected for foreground processes (the specific bioenergy system), while reputable, relevant background databases (e.g., ecoinvent, Agri-footprint) should be used for upstream inputs like fertilizer production or machinery.
Experimental Protocols
Protocol 1: Defining the Functional Unit and Reference Flows
Objective: To establish a precise, defensible functional unit and calculate the corresponding reference flows for the product system. Materials: Process flow diagram, mass and energy balance data for the bioenergy conversion process, product specifications. Methodology:
- Identify the primary function of the system (e.g., to provide motive power for light-duty vehicles).
- Consult relevant industry or policy standards (e.g., ASTM D7864 for aviation turbine fuel) to define a measurable FU (e.g., 1 MJ of lower heating value (LHV) of hydroprocessed ester and fatty acid (HEFA) jet fuel).
- Using mass/energy balance models, calculate the exact amount of feedstock (e.g., 3.2 kg of waste cooking oil), processing chemicals, and energy inputs required by the defined system to deliver 1 MJ of HEFA fuel. These are the reference flows.
- Document all assumptions and conversion factors (e.g., LHV values).
Protocol 2: Scoping Inventory Data Collection via Process Modeling
Objective: To generate a primary life cycle inventory (LCI) for the core conversion process using process simulation software. Materials: Process simulation software (e.g., Aspen Plus, SuperPro Designer), operational data (temperature, pressure, yields, catalyst loadings), feedstock ultimate/proximate analysis. Methodology:
- Develop a steady-state model of the bioenergy conversion pathway (e.g., biomass gasification followed by Fischer-Tropsch synthesis).
- Input validated kinetic models and thermodynamic parameters.
- Define the system boundaries within the model to match the LCA scope (e.g., from biomass inlet to upgraded bio-crude outlet).
- Run the simulation to achieve mass and energy closure.
- Extract the consumption and emission data per unit of primary product (the reference flow) to create the foreground LCI dataset compatible with OpenLCA (e.g., flows for biomassin, naturalgasin, FTdieselout, CO2emission_pt).
Protocol 3: Handling Multi-Functionality via System Expansion
Objective: To account for environmental burdens between the main product and co-products without using allocation. Materials: LCI of the analyzed system, LCI of the avoided (substituted) product system. Methodology:
- Identify all functionally relevant co-products from the bioenergy system (e.g., distillers' dried grains with solubles (DDGS) from corn ethanol production).
- Define the alternative production route for an equivalent co-product (e.g., soybean meal as a protein-rich animal feed).
- Expand the system boundary to include the avoided production of the equivalent product via the conventional route.
- In the LCA model (e.g., OpenLCA), subtract the inventory of the avoided system from the inventory of the analyzed bioenergy system. The net inventory represents the environmental impact of producing only the main product (ethanol), with credit given for displacing the conventional product.
Data Tables
Table 1: Common Functional Units in Bioenergy LCA Studies
| Bioenergy System | Typical Functional Unit | Rationale |
|---|---|---|
| Biogas for Electricity | 1 kWh of AC electricity at grid | Allows direct comparison with grid mix. |
| Bioethanol for Transport | 1 km driven by a compact passenger car | Represents the final service, accounting for engine efficiency. |
| Biodiesel (FAME) | 1 MJ of fuel (Lower Heating Value) | Standard energy basis for fuel comparisons. |
| Woody Biomass for Industrial Heat | 1 GJ of process steam at 20 bar | Represents the industrial utility provided. |
| Integrated Biorefinery | 1 operational year of the facility | Used for facility-level assessments, encompassing multiple products. |
Table 2: Exemplary System Boundary Definitions and Data Sources
| Life Cycle Stage | Included Processes (Cradle-to-Grave Example) | Typical Data Source |
|---|---|---|
| Feedstock Production | Fertilizer manufacture, seeding, irrigation, harvesting. | Primary farm data, Agri-footprint database. |
| Feedstock Transport | Diesel consumption for truck/rail transport. | Primary logistics data, Ecoinvent transport datasets. |
| Bioenergy Conversion | Pre-treatment, biochemical/thermochemical conversion, upgrading. | Primary pilot/plant data, process simulation models. |
| Energy Distribution | Electricity grid losses, biofuel pipeline/transport. | National laboratory reports (e.g., NREL), industry data. |
| End-Use / Combustion | Fuel combustion in vehicle engine, emissions. | Standard emission factors (e.g., EPA MOVES), literature. |
| Infrastructure & Capital | Manufacturing of processing equipment, plant construction. | Ecoinvent, literature approximations. |
Visualizations
LCA Project Setup Iterative Workflow
Bioenergy System Boundaries: Cradle-to-Grave
The Scientist's Toolkit
Table 3: Key Research Reagent Solutions & Materials for Bioenergy LCA
| Item | Function/Application in Bioenergy LCA Research |
|---|---|
| OpenLCA Software | Open-source LCA software for modeling, calculating, and analyzing the environmental impacts of bioenergy systems. |
| ecoinvent Database | Comprehensive background LCI database for materials, energy, transport, and waste treatment processes. |
| Agri-footprint Database | Specialized LCI database for agricultural and biomass production processes, critical for feedstock modeling. |
| Process Simulation Software (Aspen Plus, SuperPro) | Used to generate mass/energy-balanced primary data for novel conversion technologies where industrial data is lacking. |
| Biomass Property Analyzers (CHNS/O, Calorimeter) | To determine ultimate/proximate analysis and heating value of feedstocks for accurate material and energy flow modeling. |
| Literature Meta-Analysis Datasets | Curated collections of published experimental data (e.g., crop yields, conversion yields) for parameterizing models and conducting sensitivity analyses. |
| Geospatial Data (GIS) | For assessing spatially explicit factors like soil carbon changes, land use change, and logistical transport networks. |
Application Notes for OpenLCA in Bioenergy Systems Research
This protocol details the construction of a comprehensive process diagram for a bioenergy system, from feedstock cultivation to product distribution, within the OpenLCA software environment. This modeling is critical for conducting life cycle assessment (LCA) and techno-economic analysis (TEA) of bioenergy pathways, providing researchers and development professionals with a reproducible framework for evaluating sustainability metrics, carbon intensity, and process efficiency.
System Definition & Goal and Scope
The process model is structured as a cradle-to-gate (or cradle-to-grave) system, with the functional unit defined as 1 MJ of delivered bioenergy fuel. The system boundary encompasses three primary stages: Feedstock Cultivation, Feedstock Conversion, and Product Distribution.
Key Quantitative Parameters (System Variables): Table 1: Common Feedstock Cultivation Data (Regional Averages, US)
| Parameter | Corn Stover | Switchgrass | Woody Biomass | Unit |
|---|---|---|---|---|
| Yield (Dry Mass) | 4.5 | 10.0 | 8.0 | tonne/ha/yr |
| Fertilizer (N) Requirement | 120 | 50 | 0-20 | kg N/ha/yr |
| Water Consumption | 600 | 300 | 150 | mm/yr |
| Soil Carbon Sequestration Potential | Low | Medium-High | High | Qualitative |
Table 2: Conversion Process Efficiencies (Current State of Technology)
| Conversion Pathway | Feedstock Input (Dry Tonne) | Primary Product Output | Conversion Efficiency (Energy Basis) |
|---|---|---|---|
| Biochemical (e.g., Ethanol) | 1 Corn Stover | 330 L Ethanol | ~50-55% |
| Thermochemical (e.g., Gasification/F-T) | 1 Woody Biomass | 1100 MJ Synthetic Diesel | ~45-50% |
| Anaerobic Digestion (Wet Feedstocks) | 1 Manure | 85 m³ Biomethane | ~40-45% |
Detailed Experimental & Modeling Protocols
Protocol 2.1: Inventory Data Compilation for Feedstock Cultivation Objective: To collect primary or secondary life cycle inventory (LCI) data for the agricultural phase. Materials: Regional agricultural statistics databases (e.g., USDA NASS), peer-reviewed LCA literature, soil property maps. Methodology:
- Define Crop Management Practice: Specify tillage (conventional, no-till), fertilization rate (kg/ha), irrigation volume (m³/ha), and pesticide application (kg active ingredient/ha).
- Gather Input Data: For each defined practice, collect data on:
- Direct inputs: Seeds, fertilizers, pesticides, diesel for machinery.
- Direct emissions: N₂O from soil, NOₓ from machinery, phosphate runoff.
- Land use change: Account for direct/indirect land use change (d/iLUC) emissions using models like GREET or IPCC Tier 1 methods.
- Allocate Co-products: If the crop produces grain and stover, allocate impacts using mass, energy, or economic allocation ratios (e.g., 85% to grain, 15% to stover based on dry mass).
- Data Formatting: Structure data per ISO 14044 standards for import into OpenLCA as a
.csvfile or via native database links (e.g., ecoinvent, Agri-footprint).
Protocol 2.2: Modeling Biochemical Conversion in OpenLCA Objective: To create a process flow for enzymatic hydrolysis and fermentation. Materials: OpenLCA software, process engineering models (e.g., ASPEN Plus simulations), peer-reviewed literature on conversion yields. Methodology:
- Create Unit Processes: In OpenLCA, create distinct unit processes for: Pretreatment (e.g., dilute acid), Enzymatic Hydrolysis, Fermentation, and Product Recovery (distillation).
- Define Flows: Create technosphere (intermediate) and elementary (emissions to environment) flows for all inputs/outputs (enzymes, yeast, process water, CO₂ emissions from fermentation, wastewater).
- Link Processes: Connect outputs of one process as inputs to the next, ensuring mass/energy balance. Use "Product" flows to link the chain.
- Parameterize: Create parameters for key variables (e.g.,
enzyme_dose = 20 mg/g cellulose,sugar_to_ethanol_yield = 0.51 g/g). This allows for scenario analysis. - Validate: Compare total feedstock input to final product output (e.g., L ethanol/tonne biomass) against established benchmarks from literature (see Table 2).
Protocol 2.3: Conducting Uncertainty & Sensitivity Analysis Objective: To assess the robustness of the model's environmental impact results. Materials: OpenLCA with optional add-ons, statistical software (R, Python). Methodology:
- Define Uncertainty Distributions: For key parameters (e.g., crop yield, conversion efficiency), assign probability distributions (e.g., normal, log-normal, uniform) based on data range.
- Run Monte Carlo Simulation: In OpenLCA, navigate to Calculate > Uncertainty Analysis. Set iterations (e.g., 1000).
- Analyze Output: Determine which input parameters contribute most to variance in impact categories (Global Warming Potential, Acidification) using sensitivity indices (e.g., Spearman correlation).
- Report: Present results as mean impact values with confidence intervals (e.g., 95%).
The Scientist's Toolkit: Research Reagent Solutions & Essential Materials
Table 3: Key Materials for Bioenergy Pathway Research
| Item / Reagent | Function / Application in Research |
|---|---|
| Cellulase Enzyme Cocktails (e.g., CTec2, HTec2) | Hydrolyzes cellulose and hemicellulose in biomass to fermentable sugars during biochemical conversion studies. |
| Genetically Modified Yeast Strains (e.g., S. cerevisiae SY8) | Ferments C5 and C6 sugars to ethanol or other advanced biofuels; used in yield optimization experiments. |
| Gas Chromatography-Mass Spectrometry (GC-MS) | Analyzes composition of bio-oils, syngas, and final fuel products for purity and hydrocarbon distribution. |
| Life Cycle Inventory (LCI) Databases (ecoinvent, USLCI) | Provides background data on upstream processes (electricity grid, chemical production) for system boundary completion in OpenLCA. |
| Soil Organic Carbon (SOC) Analysis Kits | Quantifies carbon sequestration potential in feedstock cultivation soils, a critical parameter for net carbon accounting. |
| Process Modeling Software (ASPEN Plus, SuperPro Designer) | Used for rigorous mass/energy balance and engineering cost analysis before LCA modeling in OpenLCA. |
Process Diagram Visualizations
Title: Feedstock Cultivation Process Flow
Title: Bioenergy Conversion Pathways
Title: OpenLCA Modeling Workflow
Application Notes for OpenLCA in Bioenergy Systems Research
The application of OpenLCA to bioenergy supply chains enables a systematic, process-based assessment of environmental impacts from feedstock cultivation to energy conversion and distribution. These notes provide a structured methodology for modeling complex, multi-output bioenergy systems, crucial for research into sustainable biofuel and biopower development.
System Definition & Goal and Scope
- Objective: To construct a cradle-to-gate life cycle inventory (LCI) for a bioenergy product (e.g., bioethanol from lignocellulosic biomass).
- System Boundary: Includes biomass cultivation, harvesting, transportation, pre-treatment, biochemical conversion (hydrolysis & fermentation), and product purification. Co-products (e.g., lignin, biogas) must be accounted for via allocation or system expansion.
- Functional Unit: 1 MJ of lower heating value (LHV) of bioethanol, or 1 kg of product.
- Software Setup: In OpenLCA, create a new project and select the "ILCD 1.0.8 2016 Midpoint+" or "ReCiPe 2016" impact assessment method suite.
Primary data should be sourced from peer-reviewed literature, industry reports, and databases (e.g., Ecoinvent, Agri-footprint, USDA). Secondary data for background processes (e.g., electricity grid, chemicals, diesel) should be consistent and region-specific.
Table 1: Representative Quantitative Data for Corn Stover Ethanol Supply Chain (Per Functional Unit: 1 MJ LHV Bioethanol)
| Process Stage | Key Input/Output | Quantity | Unit | Data Source Notes |
|---|---|---|---|---|
| Feedstock Production | Corn grain (co-product credit) | -0.15 | kg | Economic allocation applied |
| Nitrogen fertilizer | 1.2 | g | Regional average application rate | |
| Diesel (field operations) | 0.08 | MJ | Includes harvesting and collection | |
| Transport | Transport distance (biomass) | 50 | km | Average radius to biorefinery |
| Biorefinery | Corn stover input | 0.45 | kg | Dry mass basis |
| Enzymes (cellulase) | 0.6 | g | Based on recent hydrolysis yields | |
| Process water | 8.5 | L | Includes hydrolysis and cooling | |
| Electricity (grid mix) | 0.25 | MJ | For milling, pumping, etc. | |
| Wastewater generated | 6.0 | L | Sent to anaerobic treatment | |
| Co-product Management | Lignin solids (exported for energy) | -0.05 | kg | System expansion credit |
Critical Modeling Protocols in OpenLCA
Protocol 3.1: Handling Multi-functionality and Co-products
- Method: Apply system expansion (substitution) as the primary method per ISO 14044.
- OpenLCA Steps:
- Model the biorefinery as a process with multiple output flows (e.g.,
Bioethanol,Lignin_residue,Biogas). - For the co-product flow (e.g.,
Lignin_residue), right-click and select "Avoided product" to switch it to a negative input. - Link this negative input to a separate, credited process it displaces (e.g., "Natural Gas for Heat" or "Grid Electricity"). The credited process must be removed from the product system.
- Model the biorefinery as a process with multiple output flows (e.g.,
- Alternative: If system expansion is not feasible, use economic allocation. Calculate the revenue share of each product/co-product from the process and allocate inventory data accordingly using the "Allocation" tab in the process editor.
Protocol 3.2: Parameterization and Scenario Analysis
- Objective: Test sensitivity of results to key variables (e.g., biomass yield, conversion efficiency, transport distance).
- OpenLCA Steps:
- In the "Math" tab of a process, define parameters (e.g.,
transport_km = 50). - In the input/output flow amount field, use the parameter (e.g.,
= transport_km * 0.02for diesel consumption). - Create a new calculation setup for each scenario. Use the "Parameter" tab to globally redefine the parameter value (e.g.,
transport_km = 100) and recalculate results.
- In the "Math" tab of a process, define parameters (e.g.,
Protocol 3.3: Regionalized Impact Assessment for Agriculture
- Method: Integrate spatially differentiated data for land use and water consumption.
- Procedure:
- Source or create regionalized characterization factors (CFs) for impact methods like
AWARE(water scarcity) orLANCA(land use impacts). - In OpenLCA, create a new impact assessment method (
Database > Create new impact assessment method). - Add impact categories (e.g., "Water scarcity - Region A") and import the corresponding CFs via CSV file, linking them to the relevant elementary flows (e.g.,
Water, well [US-Midwest]). - Ensure your inventory data uses the same region-specific elementary flows.
- Source or create regionalized characterization factors (CFs) for impact methods like
Experimental Protocols for Cited Key Experiments
Protocol A: Determination of Biomethane Potential (BMP) for Digestate Co-product
- Purpose: To quantify the methane yield from anaerobic digestion of wastewater/lignin residues, providing data for system expansion credit in LCA.
- Materials: Serum bottles (500 mL), anaerobic digester inoculum, substrate (digestate sample), defined nutrient medium, gas bag, biogas composition analyzer (GC-TCD).
- Method:
- Add 300 mL of inoculum to each serum bottle.
- Add test substrate at a volatile solids (VS) ratio of inoculum to substrate of 2:1.
- Flush headspace with
N2/CO2(70:30) gas for 2 minutes to ensure anaerobiosis. - Seal bottles and incubate at 37°C with continuous agitation.
- Measure biogas production daily by water displacement or pressure transducer.
- Periodically sample biogas for methane content analysis via GC-TCD.
- Continue experiment until daily biogas production is less than 1% of cumulative production.
- Calculate ultimate methane yield (mL CH4 per g VS added) and use this value to model the credited energy process in OpenLCA.
Protocol B: Enzymatic Hydrolysis Sugar Yield Assay
- Purpose: To determine glucan-to-glucose conversion efficiency for parameterizing the biorefinery conversion process in LCA.
- Materials: Pre-treated biomass, commercial cellulase/hemicellulase cocktail, sodium citrate buffer (pH 4.8), DNS reagent, glucose standard, spectrophotometer, shaking incubator.
- Method:
- Prepare reaction mixtures containing 1% (w/v) solids in buffer with a standardized enzyme loading (e.g., 15 mg protein per g glucan).
- Incubate at 50°C with agitation (150 rpm) for 72 hours.
- Withdraw samples at 0, 6, 24, 48, and 72 hours.
- Immediately centrifuge samples to stop reaction and collect supernatant.
- Analyze reducing sugar content using the DNS method against a glucose standard curve.
- Calculate glucose yield as a percentage of theoretical maximum based on initial glucan content. This yield percentage becomes a critical efficiency parameter in the OpenLCA biorefinery model.
Visualizations
OpenLCA Bioenergy Product System & LCA Workflow
Detailed Bioenergy Supply Chain Process Map
The Scientist's Toolkit: Key Research Reagent Solutions
Table 2: Essential Materials for Bioenergy System LCA & Validation Experiments
| Item / Reagent | Function in Research | Example Product/Specification |
|---|---|---|
| Cellulase Enzyme Cocktail | Catalyzes the hydrolysis of cellulose to fermentable sugars in yield assays and process modeling. | CTec3 (Novozymes), activity ≥ 150 FBG/g. |
| Anaerobic Digester Inoculum | Provides microbial consortium for BMP assays to determine co-product energy potential. | Adapted inoculum from wastewater plant, TS ~10%. |
| DNS Reagent | Colorimetric quantification of reducing sugars in hydrolysis efficiency experiments. | 3,5-Dinitrosalicylic acid solution, spectrophotometric grade. |
| LCIA Method Database | Provides characterized impact factors for OpenLCA calculations (midpoint/endpoint). | Ecoinvent 3.8 cut-off, integrated with ReCiPe 2016. |
| Elemental Analyzer | Determines C, H, N, S content of biomass and residues for accurate mass and energy balances. | Thermo Scientific FLASH 2000 CHNS-O Analyzer. |
| Process Simulator Software | Generates mass & energy balance data for novel conversion processes for LCI creation. | Aspen Plus V12, with biomass property databases. |
| Geospatial Data Tool | Provides regionalized data for agricultural inputs and impacts in LCA. | USDA NASS Quick Stats, GIS software (QGIS). |
Application Notes: Selection of LCIA Methods in OpenLCA for Bioenergy Systems
Within the scope of thesis research applying OpenLCA software to bioenergy systems, the selection of a Life Cycle Impact Assessment (LCIA) method is a critical determinant of the results' relevance and interpretability. Bioenergy systems, encompassing feedstock cultivation, processing, conversion, and end-use, present unique modeling challenges, including biogenic carbon flows, land use change, and emissions from combustion or biodegradation. The ReCiPe, TRACI, and IPCC methods offer complementary perspectives.
1. ReCiPe 2016 (Global Midpoint and Endpoint)
- Context: Provides a harmonized global framework, ideal for assessing bioenergy's contribution to broader sustainability goals. Its hierarchical approach (midpoint to endpoint) connects emissions to tangible damage in three areas: Human Health, Ecosystems, and Resource Scarcity.
- Bioenergy Relevance: Crucial for its handling of land use (transformation and occupation) and water consumption impacts. The inclusion of climate change metrics with distinct time horizons (GWP 20, 100, 500) allows nuanced analysis of short-lived climate forcers (e.g., methane from biogas).
- Thesis Application: Best suited for comprehensive sustainability assessment and comparison of bioenergy pathways against fossil or other renewable benchmarks in a global context.
2. TRACI 2.1 (Regionalized Midpoint, U.S. Focus)
- Context: A tool developed by the U.S. EPA, utilizing U.S.-specific factors where available. It operates primarily at the midpoint level, assessing impact categories like ozone depletion, smog formation, and ecotoxicity.
- Bioenergy Relevance: Offers regionalized factors for acidification and eutrophication, which are highly relevant for assessing air and water quality impacts from agricultural feedstock production and combustion. Its regionalization provides higher spatial accuracy for North American studies.
- Thesis Application: Recommended for research focusing on the regional environmental impacts of bioenergy systems within the United States or where U.S.-specific policy context is required.
3. IPCC 2021 (Focused on Climate Change)
- Context: A single-issue method dedicated to climate change impacts, based on the Intergovernmental Panel on Climate Change's latest assessment reports (AR6). It provides Global Warming Potential (GWP) values over 20, 100, and 500-year time horizons.
- Bioenergy Relevance: The definitive method for characterizing greenhouse gas (GHG) emissions. Essential for calculating the carbon footprint and potential climate benefits of bioenergy, as it includes the most updated characterization factors for CO2, CH4, N2O, and other GHGs. It is agnostic to biogenic carbon, requiring explicit modeling of carbon flows in the life cycle inventory.
- Thesis Application: Indispensable for climate-centric research, such as evaluating bioenergy systems' compliance with GHG reduction targets or conducting carbon accounting.
Comparative Summary Table: LCIA Method Selection for Bioenergy
| Feature | ReCiPe 2016 | TRACI 2.1 | IPCC 2021 (AR6 GWP) |
|---|---|---|---|
| Geographical Scope | Global | Primarily United States | Global |
| Primary Focus | Comprehensive sustainability (18 midpoint, 3 endpoint categories) | Midpoint impacts, regionalized for U.S. (10 categories) | Climate change only (multiple time horizons) |
| Key Bioenergy-Relevant Strengths | Land use, water use, multi-horizon GWP, endpoint damage aggregation. | Regionalized acidification/eutrophication, ozone depletion, human health (particulate matter). | Authoritative, up-to-date GWP factors; clear time horizon differentiation. |
| Biogenic Carbon Handling | Requires explicit inventory modeling; method applies characterization factors. | Requires explicit inventory modeling; method applies characterization factors. | Requires explicit inventory modeling; treats biogenic CO2 as neutral unless from delayed emissions. |
| Best For | Holistic environmental profiling, global comparisons, policy support for SDGs. | Regional impact studies in North America, local air/water quality analysis. | Precise carbon footprinting, GHG mitigation potential studies, regulatory reporting. |
Experimental Protocol: Implementing a Comparative LCIA in OpenLCA
Objective: To quantify and compare the environmental impacts of a defined bioenergy system (e.g., 1 MJ of energy from corn stover ethanol) using the ReCiPe, TRACI, and IPCC methods within OpenLCA software.
I. Prerequisites & System Definition
- Software: OpenLCA (latest version) with the following databases and LCIA method packages installed via the built-in repository:
ReCiPe 2016,TRACI 2.1,IPCC 2021. - Product System: A complete, unit-process life cycle inventory (LCI) model for the bioenergy pathway must be built and validated in OpenLCA. This includes all foreground processes (e.g., farming, transport, conversion plant) and linked background data (e.g., from databases like
ecoinventorUSLCI). - Functional Unit: Clearly defined (e.g., "1 Megajoule (MJ) of lower heating value (LHV) energy delivered as fuel-grade ethanol").
- System Boundary: Cradle-to-gate or cradle-to-grave, consistently applied.
II. Computational Workflow Protocol
- Method Configuration:
- In OpenLCA, navigate to the LCIA Methods pane.
- Select and import the three required method packages from the repository if not already present.
- For ReCiPe, decide on perspective (Hierarchist recommended) and level (Midpoint recommended for detailed comparison).
- For IPCC, select the relevant time horizon (GWP100 is standard).
Impact Assessment Calculation:
- Open the saved bioenergy product system.
- Go to Calculation > Quick Calculation or Detailed Analysis.
- In the calculation setup dialog, add all selected impact categories from the three methods to the Impact assessment tab. A recommended minimum set includes:
- From ReCiPe (H) Midpoint: Global warming, Fine particulate matter formation, Terrestrial acidification, Freshwater eutrophication, Land use, Water consumption.
- From TRACI 2.1: Global Warming Air, Acidification, Eutrophication, Ozone Depletion, Smog Formation.
- From IPCC 2021: Global Warming Potential (GWP100).
- Run the calculation.
Result Export and Normalization (Optional):
- Export the LCIA results table to a CSV or Excel file for external analysis.
- For within-software comparison, use the Results section to view contributions by process.
- To compare across disparate categories, apply normalization factors (provided within each method) in post-processing (e.g., using spreadsheet software).
III. Data Analysis and Interpretation Protocol
- Tabulate Results: Create a master results table with impact categories as rows and the three methods' results for your bioenergy system as columns. Note units carefully (e.g., kg CO2-eq vs. kg SO2-eq).
- Identify Dominant Impacts: For each method, rank the impact categories by magnitude to identify environmental hotspots (e.g., is climate change or eutrophication the largest concern?).
- Cross-Method Comparison: Compare the GWP results from ReCiPe, TRACI, and IPCC. Note any differences due to underlying characterization factors or time horizons.
- Sensitivity Check: Re-run calculations using different ReCiPe perspectives (Individualist, Egalitarian) or IPCC time horizons (GWP20) to test the sensitivity of conclusions to methodological choices.
Visualization: LCIA Method Selection and Application Workflow
Title: Decision Flow for LCIA Method Application in Bioenergy LCA
The Scientist's Toolkit: Key Research Reagent Solutions for Bioenergy LCA
| Item/Software | Function in Bioenergy LCA Research |
|---|---|
| OpenLCA Software | Open-source core platform for constructing, calculating, and analyzing life cycle inventory (LCI) and impact assessment (LCIA) models. |
| ecoinvent Database | Comprehensive, background LCI database providing validated data for upstream materials, energy, transport, and waste treatment processes. |
| USLCI Database | U.S.-specific life cycle inventory data, crucial for regionalized modeling of North American bioenergy feedstocks and energy grids. |
| ReCiPe 2016 LCIA Package | Software plugin containing characterization factors for conducting a broad environmental impact assessment. |
| IPCC 2021 LCIA Package | Software plugin providing the latest Global Warming Potential (GWP) factors for climate change impact assessment. |
| Agribalyse/FAOSTAT Data | Source for region-specific agricultural input data (fertilizer, pesticide use, yields) for modeling feedstock cultivation. |
| GREET Model (ANL) | Reference tool for transportation fuel LCA; used for model benchmarking and sourcing specific emission factors for fuel pathways. |
Python/R with pylca/lcopt |
Programming environments for automating LCA calculations, sensitivity analyses, and advanced statistical processing of results. |
1. Introduction This protocol details the execution and preliminary interpretation of a hotspot analysis within OpenLBA, a critical step in the life cycle assessment (LBA) of bioenergy systems. The objective is to identify processes with the most significant environmental impact, thereby guiding subsequent, focused research and development efforts in sustainable bioenergy.
2. Experimental Protocol: Hotspot Analysis in OpenLBA
2.1. Prerequisites
- A complete, validated product system model of the bioenergy pathway (e.g., biodiesel from microalgae) is loaded in OpenLBA.
- A relevant impact assessment method (e.g., ReCiPe 2016, IPCC 2021 GWP) is selected.
- The LBA calculation has been successfully run for the defined functional unit.
2.2. Calculation Execution
- Navigate to the 'Results' section of your project.
- Select the desired LCIA result.
- Click 'Analyze' and select 'Hotspot Analysis' from the menu.
- In the configuration dialog, set the following parameters:
- Contribution Tree: Set to display contributions from processes.
- Cutoff: Typically set to 0.5% or 1.0% to filter negligible contributions.
- Impact Categories: Select all relevant categories or focus on a key indicator (e.g., Global Warming).
- Click 'Run' to execute the hotspot analysis calculation.
2.3. Data Extraction and Tabulation
- Extract the top contributing processes for each impact category.
- Record the absolute contribution (in impact units, e.g., kg CO2-eq) and the relative contribution (percentage of total impact).
3. Initial Results Interpretation & Data Presentation
Table 1: Example Hotspot Analysis for Microalgal Biodiesel (Functional Unit: 1 MJ)
| Rank | Process Name | Impact Category: Global Warming (kg CO2-eq) | Relative Contribution (%) | Key Driver Identified |
|---|---|---|---|---|
| 1 | Fertilizer Production (N) | 1.45E-02 | 38.5% | High energy input for ammonia synthesis |
| 2 | Direct Drying (Thermal) | 9.80E-03 | 26.0% | Natural gas combustion for heat |
| 3 | Agitation in PBR | 5.20E-03 | 13.8% | Grid electricity mix |
| 4 | Transesterification | 2.90E-03 | 7.7% | Methanol production |
| 5 | Transportation of Biomass | 1.50E-03 | 4.0% | Diesel fuel use |
| Total Impact | 3.77E-02 | 100% |
Table 2: Research Reagent Solutions & Essential Materials
| Item / Reagent | Function in Bioenergy LCA Research |
|---|---|
| OpenLBA Software (v2.0+) | Core platform for modeling, calculating, and analyzing LCA of bioenergy systems. |
| Ecoinvent / Agribalyse DB | Life cycle inventory database providing background data for materials, energy, and agriculture. |
| ReCiPe 2016 LCIA Method | Harmonized impact assessment method translating inventory flows into environmental impact scores. |
| Process-specific LCI Data | Primary collected data on inputs/outputs of key unit processes (e.g., algae growth yield, lipid content). |
| Uncertainty Data (SD/PDF) | Quantitative data on variability for key parameters, enabling stochastic hotspot analysis. |
4. Diagram: Hotspot Analysis Workflow
Title: Workflow for Conducting a Hotspot Analysis in OpenLCA
5. Diagram: Interpretation Logic for a Single Hotspot
Title: Decision Logic for Interpreting a Single Identified Hotspot
Solving Common OpenLCA Challenges in Bioenergy Modeling
Troubleshooting Data Gaps and Uncertainty in Bio-Based Inventories
Bio-based inventory modeling in OpenLCA for bioenergy and biochemical research is hindered by systematic data gaps and unquantified uncertainty. This compromises the reliability of Life Cycle Assessment (LCA) outcomes for decision-making in research and development. Key challenges include:
- Spatio-temporal variability in biomass feedstock properties.
- Allocation uncertainties in multi-output biorefineries.
- Lack of primary data for novel bio-based transformation processes.
- Inconsistent characterization of biogenic carbon flows.
Table 1: Common Data Gaps and Their Impact in Bio-Based LCA Inventories
| Data Gap Category | Typical Parameters Affected | Reported Range/Value | Impact on Results (GWP Example) | Source (Primary Search) |
|---|---|---|---|---|
| Feedstock Composition | Lignin, cellulose, hemicellulose content | Variability up to ±30% for agricultural residues | Can alter biorefinery yield predictions, affecting GWP by ±15% | Recent agri-waste studies (2023-2024) |
| Soil Carbon Change (Direct Land Use) | SOC stock change factor | -0.5 to +1.2 t C ha⁻¹ yr⁻¹ for perennial crops | Dominates cradle-to-gate GWP; can shift result from net-negative to net-positive | Meta-analysis of bioenergy LCAs (2024) |
| Process Efficiency (Novel Pathways) | Catalyst yield, enzyme loading, fermentation titer | Often estimated from lab-scale (<1L) data | Scaling uncertainty can introduce over 50% error in energy and material inputs | Review of TEA/LCA integration (2023) |
| Allocation Factors | Mass, economic, energy-based allocation | Divergence >40% between mass and economic allocation for corn ethanol | Drives major shifts in burden assignment between co-products | Industry data compilation (2024) |
Application Notes & Protocols
Protocol 3.1: Systematic Uncertainty Propagation in OpenLCA
Aim: To quantify combined uncertainty from parameter variability and model choices.
Workflow:
- Parameterize the Model: Replace all fixed inputs (e.g., biomass yield, conversion rate, transport distance) with parameters in OpenLCA.
- Define Probability Distributions: Assign distributions using Pedigree matrix or primary data.
- Example:
Biomass_Yield ~ N(12, 1.5) tDM/ha(Normal distribution). - Example:
Enzyme_Loading ~ U(10, 20) mg/gDM(Uniform distribution).
- Example:
- Configure Monte Carlo Simulation:
- Navigate to
Analysis > Monte Carlo Simulation. - Set iterations to ≥10,000 for stable output.
- Select output indicators (GWP, FDP, etc.).
- Navigate to
- Execute and Analyze:
- Run simulation.
- Export results and analyze confidence intervals, contribution to variance.
- Identify top 5 parameters contributing to overall variance.
Protocol 3.2: Hybrid Data Bridging for Novel Processes
Aim: To create interim inventory data for lab-scale processes lacking industrial data.
Methodology:
- Collect Primary Lab Data: Document all material/energy inputs and outputs for the bench-scale experiment (e.g., 1L fermentation). Use stoichiometric equations.
- Scale via Surrogate Process: Identify a technologically analogous commercial process in an OpenLCA database (e.g., conventional ethanol fermentation).
- Develop Scaling Factors: Calculate intensity ratios (e.g., kWh/kg product) for the surrogate.
- Create Hybrid Unit Process: Apply scaling factors to lab-scale input/output masses, adjusted for key thermodynamic differences (e.g., heat loss scaling).
- Annotate and Flag: Clearly label the process as
Hybrid - Estimated for Researchand document all assumptions.
Visualization of Workflows
Uncertainty Propagation in OpenLCA
Hybrid Data Bridging Workflow
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Tools for Bio-Based Inventory Research
| Item / Reagent | Function in Research Context |
|---|---|
| OpenLCA with PLUS & EPD Extension | Core LCA software. Extensions enable parameterized modeling and integration of third-party EPD data. |
| ecoinvent or AGRIBALYSE Database | Provides critical background LCI data for energy, chemicals, and agricultural inputs. |
| Pedigree Matrix & Uncertainty Factors | Quantitative tool for estimating data quality and defining uncertainty distributions for stochastic modeling. |
| Biorefinery Process Simulation Software (e.g., Aspen Plus, SuperPro Designer) | Generates scaled-up, mass-and-energy-balanced inventory data for novel processes from lab parameters. |
| Elemental & Proximate Analyzer | Determines precise C, H, O, N, S, ash, and moisture content of novel biomass feedstocks for accurate modeling. |
| Life Cycle Impact Assessment (LCIA) Methods (EF 3.1, ReCiPe 2016) | Standardized methods for translating inventory flows into environmental impact indicators. |
Within the broader thesis on OpenLCA software application for bioenergy systems, resolving multi-functionality is a critical methodological challenge. Biorefineries, by design, produce multiple co-products (e.g., biofuels, biochemicals, biomaterials) from a single feedstock, creating allocation problems in Life Cycle Assessment (LCA). Accurate allocation is paramount for assigning environmental impacts (e.g., GHG emissions, energy use) fairly among products, which directly informs policy, process optimization, and comparative assertions in research and industrial drug development where bio-based platform chemicals are increasingly relevant.
Application Notes: Quantitative Data on Allocation Methods
The choice of allocation method significantly alters the LCA results for biorefinery co-products. The following table summarizes data from recent case studies on a lignocellulosic biorefinery producing ethanol and lignin.
Table 1: Comparison of Allocation Methods for a Lignocellulosic Biorefinery (per 1,000 kg dry biomass input)
| Allocation Method | Basis | Ethanol (500 L) | Lignin (200 kg) | Key Implication |
|---|---|---|---|---|
| System Expansion (Substitution) | Avoided production of equivalent product | 100% of burden, minus credit for avoided phenol | Burden allocated to replaced phenol | Result highly sensitive to chosen substituted product market. |
| Physical Allocation | Lower Heating Value (LHV) | 65% of total burdens (~8.2 MJ/L) | 35% of total burdens (~13 MJ/kg) | Common but may not reflect economic drivers. |
| Economic Allocation | Market price (Eth: $0.5/L, Lig: $1.2/kg) | 51% of total burdens | 49% of total burdens | Prices are volatile; can shift burden significantly. |
| Mass Allocation | Dry mass output | 71% of total burdens | 29% of total burdens | Simple but can undervalue energy-intensive co-products. |
Experimental Protocols for Allocation Factor Determination
Protocol 3.1: Determining Lower Heating Value (LHV) for Physical Allocation
- Objective: To experimentally determine the LHV of biorefinery co-products for use as a physical allocation parameter.
- Materials: Bomb calorimeter (e.g., IKA C2000), pellet press, dry co-product samples (e.g., lignin powder, solid hydrochar), benzoic acid calibration standard.
- Procedure:
- Calibrate the bomb calorimeter using a 1.0g benzoic acid standard pellet.
- Precisely weigh (~0.5-1.0g) the co-product sample. Form a pellet if necessary.
- Assemble the bomb with the pellet in the crucible, filling with 30 bar of pure oxygen.
- Submerge the bomb in the calorimeter's water jacket. Initiate combustion.
- Record the temperature rise (ΔT) of the water jacket.
- Calculate the Higher Heating Value (HHV) using the instrument's energy equivalent.
- Convert HHV to LHV using the formula:
LHV (MJ/kg) = HHV - (2.442 * 0.09 * H), where H is the mass fraction of hydrogen in the sample (determined via elemental analysis).
- Data Integration in OpenLCA: Enter the calculated LHV (MJ/kg) for each co-product as a flow property. Use the "Physical Allocation" function, selecting LHV as the basis.
Protocol 3.2: Conducting a Market Analysis for Economic Allocation
- Objective: To establish a robust, time-relevant market price for co-products to serve as an economic allocation factor.
- Materials: Market intelligence databases (e.g., ICIS, Bloomberg ChemWire), scientific literature, industry reports, customs/trade data.
- Procedure:
- Define Product Specification: Precisely define the co-product grade (e.g., Technical Lignin, 95% purity).
- Data Sourcing: Collect price data for the past 24-36 months from a minimum of three independent sources.
- Geographic Averaging: If the market is global, calculate a volume-weighted average price for key producing/consuming regions (North America, EU, Asia).
- Temporal Averaging: Compute a rolling annual average price to buffer short-term volatility.
- Currency & Unit Normalization: Convert all prices to a consistent currency (e.g., USD) and unit (e.g., $/kg).
- Sensitivity Analysis: Define a price variation range (e.g., ±20%) for scenario modeling in LCA.
- Data Integration in OpenLCA: Input the derived average price into the "Flow Properties" of each co-product flow. Apply economic allocation in the process dialog for the multi-output biorefinery process.
Visualization of Allocation Decision Workflow
Diagram Title: Decision Hierarchy for Solving Multi-Functionality in LCA
The Scientist's Toolkit: Key Research Reagent Solutions
Table 2: Essential Materials for Biorefinery LCA & Allocation Research
| Item / Reagent | Function & Application |
|---|---|
| IKA C2000 Bomb Calorimeter | Determines the Higher Heating Value (HHV) of solid and liquid co-products, the foundational data for physical allocation based on energy content. |
| CHNS/O Elemental Analyzer | Quantifies carbon, hydrogen, nitrogen, sulfur, and oxygen content in biomass and co-products. Critical for calculating LHV and characterizing material flows. |
| NREL LAPs (Laboratory Analytical Procedures) | Standardized protocols for biomass composition analysis (e.g., carbohydrate, lignin content). Ensures reproducible feedstock and output characterization. |
| ICIS or Bloomberg ChemWire Subscription | Provides authoritative, current, and historical market price data for biofuels and platform chemicals, enabling robust economic allocation. |
| Ecoinvent or USDA Databases | Provides background LCI data for upstream inputs (fertilizers, electricity) and substituted conventional products (e.g., phenol, ethylene) for system expansion. |
| OpenLCA with PALA DB Plugin | Core software for modelling the biorefinery system. The PALA database provides specialized bioenergy flow data, integrating experimental allocation factors. |
1. Introduction & Context Within OpenLCA-based bioenergy systems research, optimizing model performance is critical for handling the computational complexity of multi-pathway analyses. This protocol details methods for structuring life cycle inventory (LCI) data, managing parameterized scenarios, and enhancing computational efficiency to support robust decision-making in biorefinery and bio-pharmaceutical feedstock development.
2. Key Data Structures for Multi-Pathway Systems Effective modeling requires consolidated data. Table 1 summarizes core flow data for a lignocellulosic bioethanol system with coupled biochemical production pathways.
Table 1: Consolidated Inventory Data for a Multi-Pathway Lignocellulosic Biorefinery (per 1,000 kg dry feedstock)
| Flow Name | Category | Amount | Unit | Pathway Association |
|---|---|---|---|---|
| Corn Stover (input) | Resource | 1000 | kg | All |
| Dilute Acid Pretreatment | Technosphere | 150 | kg | Pretreatment |
| Cellulase Enzyme | Technosphere | 20 | kg | Enzymatic Hydrolysis |
| Glucose | Intermediate Flow | 520 | kg | Sugar Platform |
| Xylose | Intermediate Flow | 210 | kg | Sugar Platform |
| C6 Ethanol (Fermentation) | Product | 265 | kg | Biofuel Pathway |
| Succinic Acid (Fermentation) | Product | 95 | kg | Biochemical Pathway |
| Lignin Residue (Combusted) | Waste for Energy | 280 | kg | Energy Recovery Pathway |
| Process Water | Technosphere | 4500 | kg | All |
| Net Electricity Export | Product | +125 | kWh | Energy Recovery Pathway |
| CO2 (Biogenic) | Emission | 480 | kg | Fermentation |
3. Experimental Protocol: Dynamic Parameterization for Scenario Analysis
Objective: To evaluate environmental impacts under varying technological and market conditions using OpenLCA’s parameter feature.
Materials: OpenLCA 2.x, a defined product system (e.g., bioethanol+succinic acid), parameterized LCI database.
Procedure:
1. Define Global Parameters: In the OpenLCA database, create parameters for feedstock_yield (e.g., 80-120 kg/MJ), enzyme_efficiency (0.8-1.2), and coproduct_allocation_ratio (0.3-0.7 based on market price scenarios).
2. Apply Parameters in Processes: Replace static values in process amounts with {parameter_name}. For example, set glucose output amount to {enzyme_efficiency} * 520.
3. Create Parameter Sets: Define specific scenarios (e.g., "High Yield," "Low Enzyme Cost") as unique combinations of parameter values.
4. Run Calculation Set: Use the "Calculate with parameter set" function. Perform LCIA calculation (e.g., TRACI 2.1, IPCC GWP 100a) for each defined scenario.
5. Export Results: Export results as a CSV matrix for comparative analysis. Key outputs: GWP (kg CO2-eq/MJ), cumulative energy demand (MJ/MJ), and water use (L/MJ) per scenario.
Analysis: Identify scenario(s) where the multi-pathway system outperforms fossil reference systems across multiple impact categories.
4. Protocol for Computational Performance Optimization
Objective: Reduce calculation time for Monte Carlo uncertainty and sensitivity analysis on complex systems.
Procedure:
1. Database Indexing: Ensure all processes and flows have unique, consistent IDs. Use the database check function to repair references.
2. System Build Optimization: When building the product system, select "Prefer product systems" and set a cutoff for small flows (e.g., <0.5% of total mass/energy).
3. Matrix Export for Advanced Analysis: For >10,000 Monte Carlo runs, export the technology matrix (A) and intervention matrix (B) via the "Matrix Export" tool. Perform iterative simulations using external statistical software (R, Python) with matrix algebra (s = A⁻¹ * f).
4. Memory Allocation: Allocate ≥4 GB RAM to OpenLCA via the -Xmx4g flag in the startup configuration file for models with >500 processes.
5. The Scientist's Toolkit: Essential Research Reagent Solutions
| Item/Category | Example Product/Source | Function in Bioenergy Systems Modeling |
|---|---|---|
| LCA Software & Database | OpenLCA, Ecoinvent 3.9, Agribalyse | Core platform for modeling, inventory data, and impact assessment. |
| Biochemical Pathway Simulator | COPASI, CellNetAnalyzer | Models kinetics of fermentation & enzymatic pathways for yield data. |
| Parameter Estimation Tool | GREG, Python SciPy | Calibrates model parameters from experimental data (e.g., yield curves). |
| Uncertainty Distributions Database | Pedigree Matrix (ecoinvent), USLCI | Provides data quality indicators for stochastic modeling. |
| High-Performance Computing (HPC) Service | Amazon EC2, university cluster | Enables large-scale Monte Carlo simulations and multi-scenario optimization. |
| Data Visualization Library | Python Matplotlib/Seaborn, R ggplot2 | Creates publication-quality graphs for comparative LCIA results. |
6. Visualizations
Diagram 1: Multi-Pathway Bioenergy System in OpenLCA (83 chars)
Diagram 2: Scenario Analysis & Optimization Workflow (62 chars)
Addressing Temporal and Geographical Specificity in Agricultural Feedstock Data
Accurate life cycle assessment (LCA) of bioenergy systems in OpenLCA is critically dependent on the precision of agricultural feedstock data. The core thesis within which this protocol operates asserts that neglecting temporal (inter-annual yield variability, climate effects) and geographical (soil type, local agricultural practices) specificity in inventory data leads to significant uncertainty in environmental impact calculations, invalidating comparisons between energy systems. These Application Notes provide methodologies to source, process, and integrate high-resolution spatiotemporal data into OpenLCA workflows for robust bioenergy research.
Application Notes: Sourcing and Processing Spatiotemporal Feedstock Data
Table 1: Primary Data Sources for Agricultural Feedstock Inventories
| Data Category | Example Source (Current as of 2023-2024) | Temporal Resolution | Geographical Resolution | Key Parameter Provided |
|---|---|---|---|---|
| Yield & Production | USDA NASS Quick Stats, EUROSTAT | Annual, Seasonal | County/Region-level (US), NUTS-2 (EU) | Crop yield (ton/ha), harvested area |
| Climate Data | NASA POWER, ERA5 (Copernicus) | Daily, 8-day, Monthly | ~0.5° x 0.5° lat/lon | Solar radiation, precipitation, min/max temperature |
| Soil & Land | SoilGrids (ISRIC), HWSD | Static (updated periodically) | 250m raster | Soil organic carbon, pH, texture, bulk density |
| Agricultural Practices | FAOSTAT, EDGAR-FOOD | Annual | National, Sub-national | Fertilizer application rates, irrigation practices |
| Land Use Change | Global Forest Watch, MODIS Land Cover | Annual | 500m raster | Land cover classification change over time |
Data Harmonization Protocol for OpenLCA Integration
Protocol 2.2.1: Creating a Spatiotemporally Explicit Inventory Dataset Objective: To transform raw, disparate data from Table 1 into a formatted unit process dataset usable in OpenLCA for a specific crop and region.
- Define System Boundaries & Resolution: Determine the geographical unit (e.g., US county, EU NUTS region) and time period (e.g., 5-year average for 2018-2022 to smooth anomalous years).
- Data Extraction:
- For the target region and time period, extract yield data from primary sources (e.g., USDA NASS API).
- Extract corresponding climate data (e.g., growing degree days, precipitation) for the same region and time window from climate archives.
- Extract static soil property data for the region's geographical coordinates.
- Calculate Input Flows: Model fertilizer, pesticide, and water inputs as functions of yield, climate, and soil using established agro-ecological models (e.g., IPCC Tier 2 methods, SALCA). For example:
N-fertilizer (kg/ha) = (Target Yield (kg/ha) * Crop N Content) / Nitrogen Use Efficiencywhere Target Yield is the observed spatially-explicit yield. - Address Temporal Variability: Create multiple inventory datasets for the same region representing different climatic years (e.g., a dry year, a wet year, an average year) using the annual climate data.
- Format for OpenLCA: Structure the data as a .CSV file with columns:
Process Name,Geography(using region codes),Start Date,End Date,Input/Output Flow,Flow Category,Amount,Unit. Import using the OpenLCA CSV import wizard.
Table 2: Illustrative Data: Corn Grain Yield Variability in Iowa, USA (2018-2022)
| Year | Average Yield (bu/acre) | State-wide Total Production (Million bushels) | Key Climate Anomaly (vs. 30-yr avg) |
|---|---|---|---|
| 2018 | 196 | 2496 | Wet spring, moderate summer |
| 2019 | 182 | 2582 | Historic wet planting season |
| 2020 | 192 | 2543 | Derecho storm damage in August |
| 2021 | 205 | 2740 | Favorable growing conditions |
| 2022 | 200 | 2450 | Drought conditions in summer |
| 5-yr Avg | 195 | 2562 | -- |
Experimental Protocols for Empirical Data Collection
Protocol for Field-Level Validation of Inventory Data
Title: Field Sampling for Spatiotemporal LCA Validation of Bioenergy Feedstock.
Objective: To collect ground-truth data on crop yield and input application for validating and refining geographically-specific LCI datasets.
Materials & Methods:
- Site Selection: Use stratified random sampling across the target region based on soil type and historical yield maps.
- Plot Establishment: Establish monitoring plots (min. 10m x 10m) within representative fields for the target crop (e.g., switchgrass, maize).
- Temporal Data Logging: Install connected sensors (e.g., soil moisture, local weather station) to log data at sub-daily intervals for the growing season.
- Input Tracking: Work with cooperating farmers to obtain exact records of all seed, fertilizer (type, amount, date), pesticide, and irrigation applications for the monitored plots.
- Yield Measurement: At physiological maturity, harvest the entire plot or use standardized quadrant sampling to determine fresh weight. Subsample for moisture content analysis to report dry mass yield (ton/ha).
- Soil & Biomass Analysis: Collect pre-planting and post-harvest soil cores for nutrient analysis (N, P, K). Analyze biomass subsample for elemental composition (CHNS) and calorific value.
Deliverable: A plot-specific dataset linking quantified inputs, climate conditions, and output yield/biomass quality for direct input into or validation of an OpenLCA unit process.
Protocol for Integrating Temporal Weather Variability into LCA Models
Title: Monte Carlo Simulation of Climate Variability in OpenLCA.
Objective: To propagate the inter-annual variability of climate-sensitive parameters (e.g., yield, irrigation demand) through an LCA model.
Methodology:
- Define Stochastic Parameters: Identify key input flows with high climate sensitivity (e.g.,
Water, irrigation,Ammonium nitrate fertilizer,Crop yield). - Fit Probability Distributions: Using 20-30 years of historical data for the target region, fit statistical distributions (e.g., Normal, Weibull) to the annual values of each parameter. For yield, model it as a function of growing degree days (GDD) and precipitation using regression.
- Configure OpenLCA: For the base process, convert the static values of the stochastic parameters to parameters (e.g.,
YIELD,IRRIGATION). - Define Uncertainty Distributions: In the OpenLCA parameter table, assign the fitted probability distribution (mean, SD) to each parameter.
- Run Monte Carlo Simulation: Use the OpenLCA calculation setup with
Monte Carlo Simulationselected (minimum 1000 iterations). - Analyze Results: Export the distribution of LCIA results (e.g., GWP, eutrophication) and calculate confidence intervals. The output quantifies the uncertainty in impact assessments due to temporal climate variability.
Visualization of Methodological Workflows
Title: Workflow for Spatiotemporal Feedstock Data Integration in LCA
Title: Modeling Spatially-Explicit Agricultural Inventory Flows
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Toolkit for Spatiotemporal Agricultural LCA Research
| Item/Category | Example Product/Source | Function in Research |
|---|---|---|
| Geospatial Data Platform | Google Earth Engine, QGIS with GRASS | For accessing, processing, and visualizing raster/vector data (yield maps, soil, climate) at scale. |
| Climate Data API | NASA POWER API, CDS (Copernicus) API | Programmatic access to long-term, gap-filled historical climate data for any location. |
| Agro-Modeling Library | DSSAT (Crop Model), R packages (agro, soilassessment) |
To simulate crop growth and input requirements based on specific soil and daily weather data. |
| Data Harmonization Tool | OpenLCA CSV Import Template, Python (pandas, geopandas) |
To clean, align, and transform diverse data sources into the strict format required by LCA software. |
| Field Sensor Package | METER Group sensors (e.g., TEROS 12 for soil moisture), Onset HOBO weather stations | For collecting ground-truth temporal data on micro-climate and soil conditions to validate models. |
| Biomass Analysis Service | External CHNS/O Analyzer, Bomb Calorimeter | To determine the elemental composition and calorific value of feedstock samples, critical for bioenergy LCIA. |
| Uncertainty Analysis Package | OpenLCA native Monte Carlo, R package (mc2d) |
To define probability distributions for input parameters and propagate uncertainty through the LCA system. |
Best Practices for Data Quality Management and Documentation
Introduction This document establishes Application Notes and Protocols for Data Quality Management (DQM) within the context of Life Cycle Assessment (LCA) research on bioenergy systems using OpenLCA software. High-quality, well-documented data is critical for ensuring the reliability, reproducibility, and credibility of LCA results, which inform decisions in research, policy, and industrial development.
Application Note 1: Data Quality Assessment (DQA) Framework for LCI Data Life Cycle Inventory (LCI) data quality directly impacts result uncertainty. A systematic DQA based on the Pedigree Matrix approach is essential.
Table 1: Pedigree Matrix for LCI Data Quality Scoring
| Quality Indicator | Score 1 (High Quality) | Score 3 (Medium Quality) | Score 5 (Low Quality) |
|---|---|---|---|
| Reliability | Verified data based on measurements | Non-verified data from source or qualified estimate | Non-qualified estimate or personal communication |
| Completeness | Representative data from all relevant sites/time periods | Representative data from >50% of sites/time | Representative data from <50% of sites/time |
| Temporal Correlation | Data age <3 years | Data age 3-10 years | Data age >10 years |
| Geographical Correlation | Data from study area | Data from adjacent area with similar conditions | Data from unknown or significantly different area |
| Technological Correlation | Data from specific process under study | Data from similar, non-identical process | Data from a different, aggregated technology |
Protocol 1.1: Implementing the Pedigree Matrix in OpenLCA Workflow
- Data Collection & Entry: For each flow and process in your bioenergy model, document the primary source.
- Quality Scoring: Assign a score (1-5) for each of the five indicators in Table 1. Justify each score in the process "Description" or "Documentation" field in OpenLCA.
- Aggregation (Optional): Calculate a basic aggregated DQI using the formula: DQI = Σ(Indicator Score) / Number of Indicators. Record this in a custom field.
- Review: Conduct peer-review of DQI scores across the research team to ensure consistency.
Protocol 1.2: Uncertainty Propagation via Monte Carlo Simulation
- Define Uncertainty Distributions: In OpenLCA, for each input parameter (e.g., a flow amount), define a probability distribution. Use:
- Log-normal: For most LCI data. The geometric standard deviation (GSD) can be derived from the Pedigree scores.
- Formula: A common heuristic:
log10(GSD) = 0.01 * (Sum of Pedigree Scores)^2.
- Configure Monte Carlo: Navigate to
Calculate > Analysis > Monte Carlo Simulation. - Set Iterations: For bioenergy systems with moderate complexity, 1000-10,000 iterations are recommended.
- Run Simulation: Execute the simulation. OpenLCA will calculate a distribution of results for your impact categories.
- Interpret Results: Analyze the output statistics (mean, median, standard deviation, confidence intervals) to quantify the uncertainty in your final LCA results.
Title: Data Quality and Uncertainty Workflow in OpenLCA
The Scientist's Toolkit: Key Reagents for Bioenergy LCA Research
| Item | Function in Bioenergy LCA Research |
|---|---|
| OpenLCA Software | Core platform for modeling, calculation, and result visualization of bioenergy product systems. |
| ecoinvent Database | Comprehensive, commercial LCI database providing background data for upstream/downstream processes (e.g., fertilizers, fuels, materials). |
| Agri-footprint Database | Specialized LCI database for agricultural and biomass production processes, crucial for feedstock modeling. |
| ILCD+EF Database Package | Provides impact assessment methods aligned with the European Commission's Product Environmental Footprint (PEF). |
| Elementary Flow List | A curated, consistent list of flows crossing the system boundary (e.g., CO2, NOx, heavy metals to air/water). Critical for accurate impact assessment. |
Python with olca-ipc |
Python library for scripting data import, manipulation, and automated calculations in OpenLCA, enhancing reproducibility. |
| Git / GitHub | Version control system for managing OpenLCA project files, JSON-LD exports, and scripts, enabling collaborative DQM. |
Application Note 2: Systematic Documentation Protocol Reproducibility requires documentation that extends beyond the software project file.
Table 2: Documentation Checklist for an OpenLCA Bioenergy Project
| Document Component | Content Description | Storage Location |
|---|---|---|
| Goal & Scope Definition | Explicit statement of objective, functional unit, system boundaries, allocation procedures, and impact categories. | PDF in project folder; also in OpenLCA project "Description". |
| Process Map Diagram | Visual representation of the bioenergy system's unit processes and flows. | Image file (SVG/PNG) and Graphviz DOT script in project folder. |
| Data Source Registry | Table linking each key process/flow to its primary source (with full citation, link, access date). | Spreadsheet (CSV/Excel) and/or OpenLCA process documentation fields. |
| Pedigree Matrix Scores | Record of assigned DQI scores with justifications (see Protocol 1.1). | Embedded in OpenLCA; summarized in a separate spreadsheet. |
| Model Parameters & Formulas | Documentation of all calculated parameters, variables, and mathematical relationships used. | OpenLCA parameters list; backup in README file. |
| Critical Review Notes | Record of internal or external review feedback and model adjustments made in response. | PDF report in project folder. |
Protocol 2.1: Exporting and Archiving a Fully Documented OpenLCA Project
- Internal Documentation: Complete all fields in OpenLCA (Descriptions, Comments, Sources) for processes, flows, and the overall project.
- Parameter Export: Export all project parameters to CSV (
Data > Parameters > Export). - JSON-LD Export: Create a full, self-contained archive. Use
File > Export > JSON-LD. This format preserves data, models, and basic documentation. - Package Creation: Create a ZIP archive containing:
- The JSON-LD export file.
- The exported parameters CSV.
- All files listed in Table 2.
- A
README.txtfile with instructions to open the model.
- Versioning: Assign a unique version identifier (e.g., v1.0.2) to the package and update the version in the OpenLCA project title.
Title: OpenLCA Project Documentation Archive Structure
Conclusion Adherence to these structured protocols for data quality scoring, uncertainty quantification, and comprehensive documentation ensures that LCA research on bioenergy systems in OpenLCA meets the high standards required for scientific validity and supports robust decision-making in research and development.
Validating Results and Conducting Comparative LCA Studies with OpenLCA
Methods for Sensitivity and Uncertainty Analysis in Bioenergy LCAs
This application note details protocols for sensitivity and uncertainty analysis (SA/UA) within bioenergy life cycle assessment (LCA) studies, framed within a broader thesis employing OpenLCA software. Robust SA/UA is critical for interpreting results, identifying key drivers, and quantifying the reliability of environmental impact assessments for bioenergy systems (e.g., biogas, biodiesel, woody biomass). These methods are essential for researchers and scientists to make credible, data-driven decisions in sustainable energy development.
Table 1: Common Uncertainty Types in Bioenergy LCA & Recommended Analysis Methods
| Uncertainty Type | Description | Typical Data Source | Recommended OpenLCA Analysis Method |
|---|---|---|---|
| Parameter Uncertainty | Variability or imprecision in input values (e.g., crop yield, emission factor). | Literature, measurements, expert judgment. | Global Sensitivity Analysis (Monte Carlo). |
| Scenario Uncertainty | Choices in modeling (e.g., allocation method, system boundaries). | Methodological guidelines (ISO, ILCD). | Discrete scenario analysis. |
| Model Uncertainty | Limitations of the underlying impact assessment models. | Scientific literature on model comparisons. | Comparative assessment using different LCIA methods. |
| Temporal & Spatial Variability | Differences due to location or time of data collection. | Regionalized databases, time-series data. | Geo-spatial parameterization and stochastic modeling. |
Table 2: Key Sensitivity Indices & Their Interpretation
| Index | Formula (Conceptual) | Range | Interpretation in Bioenergy Context | ||
|---|---|---|---|---|---|
| Spearman Rank Correlation Coefficient | ( r_s ) | [-1, 1] | Measures monotonic relationship between input parameter and output. Identifies key yield/input drivers. | ||
| Standardized Regression Coefficient (SRC) | ( \beta_{std} ) | (-∞, ∞) | Indicates change in output (in std dev) per unit change in input (in std dev). Prioritizes techno-economic parameters. | ||
| Morris Elementary Effect Mean (μ*) | ( \mu* = \frac{1}{r} \sum_{i=1}^{r} \left | EE_i \right | ) | ≥ 0 | Screens for parameters with substantial influence on GWP or FDP impacts. |
Experimental Protocols for SA/UA in OpenLCA
Protocol 3.1: Global Uncertainty Analysis via Monte Carlo Simulation
Objective: To quantify the uncertainty in LCA results (e.g., Global Warming Potential) for a biodiesel production model. Workflow:
- Model Development: Construct a cradle-to-gate bioenergy system model in OpenLCA, defining all processes and flows.
- Parameter Specification: For each critical input (e.g., N2O emission factor from soil, transesterification efficiency, methane slip), assign a probability distribution (e.g., Normal: Mean=0.03 kg N2O-N/kg N, SD=0.005; Uniform: Min=92%, Max=97%).
- Monte Carlo Setup: In OpenLCA, navigate to Analysis > Monte Carlo Simulation. Set the number of iterations (≥ 1000 recommended).
- Execution & Output: Run the simulation. Export results, including statistics (mean, standard deviation, confidence intervals) and contribution-to-variance data.
Protocol 3.2: Global Sensitivity Analysis Using Standardized Regression Coefficients (SRC)
Objective: To identify which input parameters most influence the variability of the net energy ratio (NER) of a biogas system. Workflow:
- Sampling: Use the Monte Carlo results from Protocol 3.1. OpenLCA internally generates the parameter sample matrix.
- Result Aggregation: For each Monte Carlo run, collect the target result (NER).
- Regression Analysis: Perform a multiple linear regression outside OpenLCA (using R, Python, or spreadsheet software) with the NER as the dependent variable and the standardized input parameters as independent variables.
NER = β0 + β1*(X1_std) + β2*(X2_std) + ... + ε - SRC Extraction: The regression coefficients (β1, β2,...) are the SRCs. Rank their absolute values to prioritize parameters (e.g., substrate volatile solids content, CHP unit efficiency).
Protocol 3.3: Scenario and Model Uncertainty Analysis
Objective: To compare the climate impact of woody biomass pyrolysis under different allocation methods and LCIA models. Workflow:
- Scenario Definition: Create three separate OpenLCA projects for the same pyrolysis system, applying mass, economic, and energy-based allocation.
- LCIA Method Selection: Calculate results using at least two impact methods (e.g., IPCC 2021 GWP 100y and ILCD 2018 Midpoint+).
- Calculation & Comparison: Calculate the total GWP for each scenario-method combination.
- Discrete Analysis: Present results in a comparative table or tornado diagram. The spread of results quantifies the combined scenario and model uncertainty.
Visualization of Workflows
Title: Monte Carlo and Sensitivity Analysis Workflow in OpenLCA
Title: Relationship Between Input Uncertainty and Output Analysis
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Toolset for SA/UA in Bioenergy LCA with OpenLCA
| Item / Solution | Function / Purpose | Example in Bioenergy SA/UA |
|---|---|---|
| OpenLCA Software + Monte Carlo Add-on | Core platform for LCA modeling and built-in stochastic simulation. | Executing Protocol 3.1 for biodiesel process uncertainty. |
| ecoinvent or AGRIBALYSE Database | Provides life cycle inventory data with pre-quantified uncertainty distributions (SD, min/max). | Sourcing uncertain data for feedstock production (e.g., corn cultivation). |
| Statistical Software (R, Python with pandas, NumPy) | For advanced statistical analysis, custom sensitivity indices, and visualization of results. | Calculating SRCs (Protocol 3.2) and generating kernel density plots of impact results. |
| Pedigree Matrix Tool | A systematic approach to quantify data quality and derive uncertainty factors based on reliability, completeness, etc. | Assigning uncertainty distributions to poorly documented technical process data. |
| Global Sensitivity Analysis (GSA) Libraries (SALib, OpenTURNS) | Provide algorithms (Sobol, Morris) for advanced variance-based sensitivity analysis. | Performing Sobol indices analysis to account for parameter interactions in a complex gasification model. |
| Uncertainty Factor Databases (ILCD, Greco et al.) | Published guidelines on default uncertainty factors for common LCA data types. | Applying log-normal standard deviations to elementary flows from literature. |
Application Notes: OpenLCA for Bioenergy Systems Research
This document provides a structured methodology for conducting comparative scenario analyses of bioenergy systems using OpenLCA. The focus is on evaluating environmental impacts across varying feedstocks, conversion technologies, and policy-driven assumptions, tailored for research professionals in bioenergy and related fields.
1.0 Core Comparative Scenarios
Scenarios are defined by the intersection of three primary variable clusters:
- Feedstock (A): Origin, type, and cultivation logistics.
- Conversion Technology (B): Process used to transform feedstock into energy carriers.
- Policy & System Assumptions (C): Boundaries, allocation methods, and credit systems.
Table 1: Quantitative Feedstock Characteristics (Per Functional Unit: 1 GJ Lower Heating Value)
| Feedstock Type | Average Dry Yield (ton/ha/yr) | Carbon Content (% dry mass) | N₂O Emission Factor (kg N₂O-N/kg N applied) | LCA Data Source (Ecoinvent v3.10) |
|---|---|---|---|---|
| Corn Stover | 4.5 | 47% | 0.01 | maize grain, at farm/US-USDA (adapted) |
| Miscanthus | 14.0 | 49% | 0.007 | miscanthus bale, at farm/CH |
| Forest Residues | 3.0 (recovered) | 51% | Not Applicable | wood chips, mixed, at forest road/CH |
| Waste Cooking Oil | - | 77% | Not Applicable | market for used cooking oil/GLO |
Table 2: Conversion Technology Performance Parameters
| Technology Pathway | Typical Feedstock | Energy Conversion Efficiency (HHV) | Key Process Co-product | System Expansion Consideration |
|---|---|---|---|---|
| Biochemical (ABE Fermentation) | Corn Stover, Miscanthus | 35-40% (to biobutanol) | Acetone, Ethanol | Displaces fossil-based solvents & fuels. |
| Thermochemical (Fast Pyrolysis) | Forest Residues, Miscanthus | 65-75% (to bio-oil) | Bio-char (solid) | Carbon sequestration potential of bio-char. |
| Catalytic Hydrotreatment | Waste Cooking Oil | >90% (to renewable diesel) | Propane (C3) | Displaces fossil LPG. |
| Anaerobic Digestion | Wet organic wastes | 40-50% (to biogas) | Digestate (fertilizer) | Displaces mineral fertilizers (N, P, K). |
Table 3: Policy & Market Assumptions for Scenario Modeling
| Assumption Category | Option 1 (Baseline) | Option 2 (Renewable Incentive) | Option 3 (Circular Economy) |
|---|---|---|---|
| System Boundary | Well-to-Wheel (WTW) | Well-to-Wheel with CCUS | Cradle-to-Grave with Recycling |
| Co-product Handling | Energy Allocation (ISO) | System Expansion/Substitution | Economic Allocation (current market prices) |
| Carbon Accounting | IPCC GWP100 | Biogenic Carbon as Neutral | Bio-Char Carbon as Permanent Sequestration (-ve flow) |
| Grid Electricity Mix | National Average (2023) | 100% Renewable (2030 Target) | Marginal (Natural Gas Combined Cycle) |
2.0 Experimental Protocols for Scenario Analysis
Protocol 2.1: Constructing Modular Unit Process Inventory Objective: To build reusable, feedstock- and technology-specific process modules in OpenLCA. Materials: OpenLCA software (v2.0+), Ecoinvent 3.10 database, feedstock-specific agronomic data from USDA or FAO sources. Methodology:
- Define Core Process: Create a new process (e.g., "Bio-butanol production, via ABE from Miscanthus").
- Link Feedstock Cultivation: Import/connect the foreground dataset for Miscanthus cultivation. Modify land use change (LUC) parameters (Table 1) in the
Inputs/Outputstab. Set direct LUC to zero for perennial crops on marginal land per policy scenario C. - Model Conversion: Add input flows for pretreatment enzymes, chemicals, and energy use based on literature-derived mass/energy balances (Table 2 efficiency).
- Handle Multi-functionality: Create separate flows for co-products (Acetone, Ethanol). Apply allocation method (mass, energy, economic) as defined per Table 3. For system expansion, create a avoided product flow linking to the displaced market process (e.g., "acetone, from fossil sources").
Protocol 2.2: Running Comparative Impact Assessment Objective: To calculate and compare the Global Warming Potential (GWP) across all scenario permutations. Materials: OpenLCA, ILCD 2018 Midpoint+ impact assessment method. Methodology:
- Build Product Systems: For each scenario combination (A1-B1-C1, A1-B1-C2, etc.), create a product system with the biofuel as the reference flow (1 GJ).
- Configure Substitution: In the
Calculationssetup, activate the "Avoided products" option for scenarios using system expansion (Table 3, Option 2). - Run Calculation & Analyze: Perform the calculation. Export the GWP results for all systems to the
Analysisview. Use theContribution Analysistool to drill into hotspots (e.g., fertilizer N₂O for Feedstock A, natural gas use for Technology B).
Protocol 2.3: Sensitivity Analysis on Key Parameters Objective: To test the robustness of the GWP ranking against data uncertainty. Materials: OpenLCA, Monte Carlo simulation add-on. Methodology:
- Define Uncertainty Distributions: For critical parameters (e.g., N₂O emission factor in Table 1, conversion efficiency in Table 2), assign lognormal or triangular distributions in the process editor (
Uncertaintytab). Use +/- 10-20% SD based on literature variance. - Configure Monte Carlo: In the calculation dialog, set simulation to
Monte Carlo, iterations = 1000. - Interpret Results: Generate confidence intervals (e.g., 95%) for each scenario's GWP. Overlapping intervals indicate that scenario rankings are not statistically significant under the given uncertainties.
3.0 Mandatory Visualizations
Diagram 1: Scenario Analysis Variable Integration in OpenLCA (93 chars)
Diagram 2: OpenLCA Scenario Modeling Workflow (59 chars)
4.0 The Scientist's Toolkit: Research Reagent Solutions
Table 4: Essential Materials & Digital Tools for Bioenergy LCA
| Item/Reagent | Function in Research | Example/Supplier |
|---|---|---|
| OpenLCA Software | Core platform for lifecycle modeling, calculation, and sensitivity analysis. | GreenDelta GmbH |
| Ecoinvent Database | Background LCI database for upstream/downstream materials, energy, and transport. | Ecoinvent Centre |
| ILCD Impact Method Set | Standardized set of life cycle impact assessment (LCIA) methods for environmental metrics. | European Commission JRC |
| NREL U.S. LCI Database | Foreground process data for specific bioenergy conversion pathways. | National Renewable Energy Lab |
| Monte Carlo Add-on | Tool for performing stochastic uncertainty and sensitivity analysis within OpenLCA. | OpenLCA Nexus |
| Agronomic Data (Yield, N-use) | Critical primary data for modeling feedstock cultivation. | FAO STAT, USDA NASS |
| Chemical Process Simulators (Aspen Plus) | To generate mass/energy balance data for novel conversion technologies (B). | AspenTech |
Within the context of OpenLCA software application to bioenergy systems research, benchmarking is a critical step for validation. This protocol details the methodology for comparing life cycle assessment (LCA) model results from OpenLCA against published peer-reviewed literature and Environmental Product Declarations (EPDs) to ensure scientific robustness and credibility.
Table 1: Benchmarking Results for Bioethanol from Corn Stover
| Impact Category (Unit) | OpenLCA Model Result | Published Literature Range | EPD Database Average | Deviation from Lit. (%) | Status |
|---|---|---|---|---|---|
| GWP100 (kg CO2-eq/MJ) | 0.045 | 0.038 - 0.052 | 0.041 | +8.5 | Within Range |
| Fossil Resource Depletion (MJ/MJ) | 0.62 | 0.55 - 0.70 | 0.58 | +5.1 | Within Range |
| Acidification (g SO2-eq/MJ) | 0.31 | 0.25 - 0.35 | 0.28 | +10.7 | Within Range |
| Eutrophication (g PO4-eq/MJ) | 0.18 | 0.12 - 0.20 | 0.15 | +20.0 | High Deviation |
Table 2: Key Inventory Flow Comparison for Biogas System
| Inventory Flow | OpenLCA Value (per m³ biogas) | Literature Reference Value | Data Source (Literature) | Notes |
|---|---|---|---|---|
| Maize Silage Input (kg) | 2.8 | 2.5 - 3.0 | Bauer et al., 2023 | Within expected range. |
| Methane Yield (m³ CH4/ton VS) | 350 | 320 - 370 | Lab ator Study, 2022 | Aligns with high-yield scenario. |
| Electricity for Mixing (kWh) | 0.15 | 0.10 | EPD No. 12345 | Higher due to model assumptions. |
Experimental Protocols
Protocol 1: Systematic Literature Review for Benchmark Data
- Objective: Collect quantitative LCA results for the bioenergy system under study.
- Search Strategy:
- Databases: Scopus, Web of Science, Google Scholar.
- Keywords: "LCA bioenergy", "life cycle assessment biodiesel", "environmental product declaration biogas", "published data [specific feedstock]".
- Filters: Publication years 2019-2024, peer-reviewed articles, English language.
- Data Extraction:
- Record system boundaries, functional unit, impact assessment method (e.g., ReCiPe 2016), and all quantitative results.
- Normalize all data to a common functional unit (e.g., 1 MJ of energy output).
- Document any critical assumptions (e.g., allocation methods, land use change).
- Analysis: Calculate the central tendency (mean/median) and range for each impact category from the literature corpus.
Protocol 2: EPD Data Collection and Harmonization
- Objective: Source industry-verified data from EPD databases.
- Sources: Access EPD libraries such as The International EPD System, Institut Bauen und Umwelt (IBU), or specific bioenergy product category rules (PCR).
- Procedure:
- Identify EPDs relevant to the bioenergy product (e.g., "Bioethanol for fuel use", "Biomethane").
- Extract the reported LCA results and underlying inventory data.
- Critical Step: Recalculate EPD results to match the impact assessment method and characterization factors used in your OpenLCA model (e.g., convert from CML to ReCiPe).
- Note any declared uncertainties.
Protocol 3: OpenLCA Model Calibration and Comparison
- Objective: Execute the comparison and calculate deviations.
- Preparatory Step: Ensure your OpenLCA model uses identical system boundaries, allocation, and impact method as the benchmark sources, or note differences.
- Execution:
- Run the OpenLCA calculation.
- For each impact category
i, calculate the percentage deviation (D) from the literature mean (Lit_mean) or EPD value:D_i = [(OpenLCA_Result_i - Lit_mean_i) / Lit_mean_i] * 100 - Acceptance Threshold: Define criteria (e.g., ±15% deviation is acceptable for complex biological systems; stricter for energy inputs).
- Sensitivity Analysis: If deviations exceed thresholds, perform a sensitivity analysis in OpenLCA on key parameters (e.g., yield, conversion efficiency, fertilizer input) to identify drivers of disparity.
Mandatory Visualization
Title: Bioenergy Model Benchmarking Workflow
Title: Data Flow for LCA Model Validation
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Tools for LCA Benchmarking Research
| Item / Solution | Function / Application in Benchmarking |
|---|---|
| OpenLCA Software (v2.0+) | Primary platform for building, calculating, and analyzing the bioenergy system LCA model. |
| OpenLCA Nexus / Ecoinvent Database | Source of background life cycle inventory data for upstream/downstream processes (e.g., electricity, chemicals). |
| ReCiPe 2016 (Midpoint) LCIA Method | Standardized set of characterization factors for impact assessment; enables direct comparison with literature. |
| Zotero / Mendeley Reference Manager | Tool for organizing and citing collected literature and EPD documents during systematic review. |
| Python (with pandas, matplotlib) | For scripting data normalization, automated deviation calculations, and generating comparative visualizations. |
| EPD Digital Search Portal (e.g., IBU) | Online platform to access and download verified Environmental Product Declarations for specific bioenergy products. |
| Sensitivity Analysis Tool (OpenLCA) | Integrated feature to test the influence of key parameters (e.g., yield, emission factors) on final results. |
Application Notes for OpenLCA in Energy Systems Research
This document provides a standardized framework for conducting a comparative Life Cycle Assessment (LCA) of energy systems using OpenLCA software, within the context of bioenergy systems research. The protocol is designed for reproducibility and aligns with ISO 14040/44 standards.
System Boundaries and Functional Unit
All assessments must use a common functional unit of 1 Megajoule (MJ) of delivered energy. The system boundary is cradle-to-grave, encompassing resource extraction, feedstock production, conversion, distribution, use, and end-of-life management. For bioenergy, this includes land use changes, cultivation, and biogenic carbon accounting. For fossil fuels, it includes exploration, extraction, and fugitive emissions. For alternative renewables (solar PV, wind, geothermal), it includes material mining, manufacturing, and decommissioning.
Critical Impact Categories & Characterization Methods
The following impact categories, calculated using the recommended methods, are mandatory for comparison:
| Impact Category | LCIA Method (in OpenLCA) | Primary Concern |
|---|---|---|
| Global Warming | IPCC 2021 GWP100 | GHG emissions (CO2, CH4, N2O) |
| Fossil Resource Scarcity | ReCiPe 2016 Midpoint (H) | Depletion of coal, oil, gas |
| Water Consumption | AWARE (Available WAter REmaining) | Freshwater scarcity |
| Land Use | ReCiPe 2016 Midpoint (H) / LANCA | Occupation & transformation |
| Particulate Matter Formation | ReCiPe 2016 Midpoint (H) | Human health, PM2.5 |
| Acidification | ReCiPe 2016 Midpoint (H) | Soil/water acidification |
Primary data should be used where possible (e.g., from pilot plants, operational data). Reliable secondary databases must be integrated into OpenLCA for background processes.
| Energy System | Recommended OpenLCA Database(s) for Background Data | Critical Foreground Data to Collect |
|---|---|---|
| Bioenergy (e.g., Corn Ethanol) | Agribalyse, Ecoinvent, USDA LCA Commons | Crop yield, fertilizer/pesticide application rates, co-product allocation method, conversion process efficiency, soil carbon flux data. |
| Fossil Fuels (e.g., Natural Gas CCGT) | Ecoinvent, ELCD (legacy) | Methane leakage rate (% of throughput), power plant efficiency (%), upstream flaring/venting data. |
| Alternative Renewables (e.g., Silicon PV) | Ecoinvent, USLCI | Panel efficiency & lifetime, irradiation data (location-specific), energy mix used in manufacturing, rare earth/mineral content. |
Experimental Protocols for Comparative LCA
Protocol: Life Cycle Inventory (LCI) Modeling in OpenLCA
Objective: To create consistent, comparable product system models for each energy carrier.
Materials & Software:
- OpenLCA software (v2.x or later)
- Relevant LCA database (e.g., ecoinvent 3.9+)
- Primary operational data spreadsheets
Procedure:
- Create a new project in OpenLCA titled "Comparative Energy LCA - [Date]".
- Import required databases into the software.
- For each energy system (Bioenergy, Fossil, Renewable):
a. Create a new product system.
b. Define the reference process (e.g., "1 MJ electricity from grid-connected biogas").
c. Build the process tree by linking unit processes (e.g., feedstock production → transport → conversion → distribution).
d. Apply allocation in case of multi-output processes (e.g., corn grain and stover). Use energy-based or economic allocation as per ISO, and document choice.
e. Link elementary flows (resource inputs, emissions to air/water/soil) for each unit process from the database or primary data.
f. Parameterize key variables (e.g.,
conversion_efficiency,transport_distance_km) to enable scenario analysis. - Validate each product system by running a quick calculation to check for missing exchanges or allocation errors.
Protocol: Impact Assessment and Comparative Analysis
Objective: To calculate and compare the environmental impacts of the defined product systems.
Procedure:
- Select the LCIA method(s) as defined in Section 1.2.
- Run the calculation for each product system.
- Export results to a CSV file.
- Perform contribution analysis within OpenLCA to identify hotspots (e.g., which process contributes most to GWP for bioethanol?).
- Conduct uncertainty analysis (if data quality supports): a. Define uncertainty distributions (e.g., lognormal) for key parameters. b. Use OpenLCA's Monte Carlo simulation tool (min. 1000 iterations). c. Analyze the overlap in impact score distributions to determine statistical significance of differences.
- Generate comparative bar charts using the OpenLCA result export and standard graphing software.
Table 1: Representative Life Cycle Impact Scores (per 1 MJ delivered energy)
| Energy System | Global Warming (g CO2-eq) | Fossil Resource Scarcity (g oil-eq) | Water Consumption (liters) | Land Use (m²a crop eq) |
|---|---|---|---|---|
| Bioenergy: Corn Ethanol | 65 - 85* | 10 - 15 | 5 - 100 (irrigation dependent) | 0.15 - 0.25 |
| Bioenergy: Forest Residue Gasification | 15 - 30 | 2 - 5 | 0.1 - 0.5 | ~0.05 (occupation) |
| Fossil: Natural Gas (CCGT) | 60 - 75 | 12 - 18 | 0.05 - 0.15 | <0.01 |
| Fossil: Coal (Pulverized) | 95 - 110 | 8 - 12 | 0.1 - 0.3 | <0.01 |
| Alternative: Silicon PV (grid) | 25 - 40 | 5 - 10 | 0.2 - 0.6 | 0.03 - 0.08 (land occupation) |
| Alternative: Wind Onshore | 7 - 12 | 2 - 4 | 0.01 - 0.03 | 0.02 - 0.05 (occupation) |
*Includes biogenic carbon and indirect land use change (iLUC) uncertainty range.
Table 2: Key Inventory Flows for Hotspot Analysis
| Flow | Corn Ethanol System | Natural Gas CCGT System | Silicon PV System |
|---|---|---|---|
| Carbon dioxide, biogenic | -70 to -60 g (sequestration) | 0 g | 0 g |
| Methane, fossil | 1 - 3 g | 1.5 - 4 g (leakage) | < 0.1 g |
| Phosphate (as P) | 10 - 20 mg (fertilizer) | < 1 mg | < 1 mg |
| Copper | < 1 mg | < 1 mg | 15 - 30 mg (in wiring/cells) |
Visualizations
Diagram 1: OpenLCA Comparative LCA Workflow
Diagram 2: Cradle-to-Grave Energy System Boundary
The Scientist's Toolkit: Research Reagent Solutions
| Item / Solution | Function in Bioenergy & LCA Research |
|---|---|
| OpenLCA Software | Core platform for modeling product systems, calculating LCIA results, and performing uncertainty/sensitivity analyses. |
| ecoinvent Database | Comprehensive, peer-reviewed background LCI database for global supply chains, essential for modeling upstream processes. |
| Agribalyse Database | Specialized database for agricultural and bio-based product LCIs, critical for accurate modeling of biomass feedstocks. |
| GREET Model (by ANL) | Transportation-focused LCA model; used to cross-validate results for biofuel and vehicle energy pathways. |
| Monte Carlo Simulation Add-on (OpenLCA) | Enables statistical uncertainty analysis by propagating parameter variances through the model. |
| Geospatial Data (e.g., GIS) | For assessing location-specific factors: soil carbon, irradiation, crop yields, and transport distances. |
| Primary Data Loggers | Sensors and SCADA systems to collect real-time efficiency, emission, and resource use data from pilot/conversion facilities. |
Interpreting Comparative Results for Stakeholder Communication and Decision Support
Application Notes
Effective communication of comparative Life Cycle Assessment (LCA) results from OpenLCA bioenergy studies is critical for stakeholder engagement and informed decision-making. This protocol bridges rigorous scientific analysis with actionable insights for researchers and industry professionals in bio-based drug development.
1.1 Core Principles for Interpretation:
- Context is Paramount: Always present results relative to the defined goal, scope, and functional unit. A biofuel favorable in climate impact may be unfavorable in water scarcity; stakeholders must understand the trade-offs.
- Uncertainty Quantification: Distinguish between significant differences and methodological noise. Use statistical ranges (e.g., Monte Carlo results) to communicate reliability.
- Normalization & Weighting: Use normalization to show the relative magnitude of impact categories. Weighting (applied transparently) can aggregate results for high-level decision support, but the underlying disaggregated data must remain accessible.
- Highlight Decision Levers: Identify and foreground key process parameters (e.g., enzyme loading, feedstock pretreatment efficiency, biogas yield) that most influence the results, directing stakeholders toward actionable improvements.
1.2 Stakeholder-Specific Translation:
- Researchers/Scientists: Require detailed access to inventory flows, assumption justifications, and sensitivity analysis data to validate and build upon the work.
- Drug Development Professionals: Focus on implications for Environmental, Social, and Governance (ESG) reporting, regulatory compliance (e.g., carbon footprint of bio-based solvents or excipients), and supply chain sustainability.
Table 1: Comparative Impact Assessment Results for Bioethanol vs. Conventional Solvent (Functional Unit: 1 kg of Anhydrous Ethanol)
| Impact Category (Method: EF 3.0) | Corn Stover Bioethanol | Sugarcane Bioethanol | Fossil-Based Ethanol | Unit | Notes |
|---|---|---|---|---|---|
| Climate change | 0.85 ± 0.12 | 0.45 ± 0.08 | 2.10 ± 0.30 | kg CO₂ eq | Bioethanol shows clear advantage |
| Water use | 120 ± 25 | 510 ± 80 | 95 ± 15 | liter | Feedstock irrigation is key driver |
| Acidification | 0.008 ± 0.002 | 0.012 ± 0.003 | 0.015 ± 0.004 | mol H+ eq | System benefits from avoided fertilizer |
| Land use | 2.1 ± 0.5 | 1.8 ± 0.4 | 0.1 ± 0.05 | m²a crop eq | Direct land use change included |
Table 2: Sensitivity Analysis of Key Parameters on GWP of Corn Stover Bioethanol
| Parameter (Baseline Value) | Variation | Resulting GWP Change | Key Stakeholder Insight |
|---|---|---|---|
| Enzyme dosage (15 mg/g glucan) | +/- 30% | -5% / +8% | Cost vs. environmental trade-off critical |
| Biomass transport distance (50 km) | +100 km | +12% | Sourcing radius is a major decision factor |
| Anaerobic digestion efficiency (75%) | +/- 10% points | -7% / +9% | Digestate management offers co-benefit |
| Co-product credit method (Energy) | Substitution to Allocation | ±15% | Methodology choice alters conclusion |
Experimental Protocols
Protocol 3.1: OpenLCA-based Comparative LCA for Bioenergy Pathways
Objective: To model, calculate, and compare the environmental impacts of two distinct bioenergy feedstocks for potential application in bio-based pharmaceutical precursor synthesis.
Materials: OpenLCA software v2.x, Ecoinvent v3.9/Agribalyse database, EF 3.0/ReCiPe impact assessment method package, primary data from lab-scale biorefinery experiments (yields, energy/chemical inputs).
Methodology:
- Goal & Scope Definition: Define functional unit (e.g., 1 MJ of combustible biofuel OR 1 kg of purified biobased chemical). Determine system boundaries (cradle-to-gate). Declare critical assumptions (e.g., allocation by energy content).
- Life Cycle Inventory (LCI) Modeling:
- Create a new project in OpenLCA.
- Model each feedstock pathway (e.g., "Corn Stover to Ethanol," "Microalgae to Biodiesel") as a distinct product system.
- Build processes for each unit operation (Pretreatment, Hydrolysis, Fermentation, Distillation, Wastewater Treatment).
- Link processes with material/energy flows using input-output exchanges.
- Integrate background data from commercial databases for upstream inputs (electricity, chemicals, transport).
- Impact Assessment:
- Select the EF 3.0 impact assessment method.
- Calculate the results for each product system.
- Perform normalization to understand the relative magnitude of each impact category.
- Interpretation & Comparative Analysis:
- Run a contribution analysis to identify hotspots within each pathway.
- Conduct a Monte Carlo simulation (1000 iterations, 95% confidence) to assess statistical significance of differences.
- Perform sensitivity analysis on at least three key parameters (see Table 2).
- Reporting: Export results to CSV. Use tables and graphs (e.g., bar charts with error bars for uncertainty) for visualization. Document all data sources and modeling choices in a companion report.
Visualization Diagrams
Title: Comparative LCA Workflow for Bioenergy
Title: Bioenergy System Boundary & Flows
The Scientist's Toolkit: Research Reagent Solutions
| Item | Function in Bioenergy LCA Research | Example/Note |
|---|---|---|
| OpenLCA Software | Open-source LCA modeling platform for constructing, calculating, and analyzing product systems. | Core modeling environment. Requires pairing with LCIA methods. |
| Ecoinvent Database | Extensive, validated database of background LCI data for materials, energy, transport, and waste management. | Essential for modeling upstream/downstream processes. Commercial license required. |
| EF 3.0 (Environmental Footprint) Method | A harmonized set of LCIA impact category indicators and characterization factors for the European context. | Recommended for consistent, policy-relevant comparisons. |
| Monte Carlo Simulation Tool | Statistical function within LCA software to propagate uncertainty from input data through the model. | Used to calculate result ranges and determine significant differences (p<0.05). |
| Pedigree Matrix & Basic Uncertainty Data | Framework for qualitatively assessing data quality and assigning quantitative uncertainty factors (e.g., lognormal variance). | Applied to primary inventory data to inform Monte Carlo analysis. |
| Agribalyse / USLCI Database | Specialized LCI databases focusing on agricultural production and regional (US) processes, respectively. | Critical for accurate modeling of bioenergy feedstock cultivation. |
| Python (with pyLCIA/pandas) | Programming environment for automating data extraction, advanced statistical analysis, and custom visualization of OpenLCA results. | Enables batch processing and complex scenario analysis. |
Conclusion
OpenLCA serves as a powerful, accessible tool for conducting rigorous Life Cycle Assessments of bioenergy systems, a task of growing importance for sustainable biotech and pharmaceutical research. This guide has outlined a complete pathway: from understanding foundational principles and constructing detailed models, to troubleshooting complex issues and validating results through comparative analysis. Mastering these steps enables researchers to critically assess the environmental trade-offs of bio-based feedstocks, waste valorization strategies, and green manufacturing processes. The future of sustainable drug development hinges on such detailed environmental accounting. By integrating robust OpenLCA practices into research workflows, professionals can generate credible, actionable data to drive innovation towards truly sustainable bioeconomies, inform R&D priorities, and substantiate environmental claims with scientific rigor.